Standard
Automated Digital Document Review (HTML)
Published 11 January 2024

© Crown copyright 2024
This publication is licensed under the terms of the Open Government Licence v3.0 except where otherwise stated. To view this licence, visit nationalarchives.gov.uk/doc/open-government-licence/version/3 or write to the Information Policy Team, The National Archives, Kew, London TW9 4DU, or email: psi@nationalarchives.gov.uk.
Where we have identified any third party copyright information you will need to obtain permission from the copyright holders concerned.
This publication is available at https://www.gov.uk/government/publications/cabinet-office-automated-digital-document-review/automated-digital-document-review-html
| Name | Tier and Category | Notes for completion | Entry (please enter all the required information in this column) |
|---|---|---|---|
| Name | Tier 1 | The attribute ‘name’ is the colloquial name used to identify the algorithmic tool. | Automated Digital Document Review |
| Description | Tier 1 | The attribute ‘description’ is a description to give a basic overview of the purpose of the algorithmic tool. It should include: - how the algorithmic tool is used - why the algorithmic tool is being used |
Government departments can generate huge volumes of digital information. This needs to be sorted into records that need to be retained as the official record and information that should be destroyed because it is redundant, outdated, trivial or ephemeral in nature, or has reached its retention period. It is important that government is able to identify and select information of value for the record in order for it to comply with the requirements of the Public Records Act 1958. To achieve this, large volumes of unorganised, legacy digital information would need to be read by records reviewers in order to identify information that should be retained as a historic record, and what should be subject to permanent destruction. The algorithm is part of a disposal methodology for digital information that allows the rapid review of high volumes of digital information that would otherwise be an extremely onerous and expensive task using traditional human review methods. The algorithm sorts information using a mixture of classifications and language patterns/key words. The outcome of a review can then be visualised to support human officers to make decisions about what information to retain. Human operators input the instructions into the software running the algorithm, and are able to review its proposed actions before confirming and executing these, or re-running the review with a revised set of parameters. Deletion would involve the human operator running a deletion command across the information collection in accordance with the recommendations flagged by the algorithm. The diagram at section 3 illustrates the stages of filtration that disposal processes include and the algorithm itself is shown at section 2 below. |
| Website URL | Tier 1 | The attribute ‘website’ is the URL reference to a page with further information about the algorithmic tool and its use. This facilitates users searching more in-depth information about the practical use or technical details.This could, for instance, be a local government page, a link to a GitHub repository or a departmental landing page with additional information. | N/A |
| Contact email | Tier 1 | The attribute ‘contact_email’ is the email address of the organisation, or team for this entry. For continuity and security purposes, we would advise using or creating a team email address instead of using an individual email address. | dkim-cdio@cabinetoffice.gov.uk |
| Organisation/ department | Tier 2 - Owner and responsibility | The attribute ‘organisation’ is the full name of the organisation, department or public sector body that carries responsibility for use of the algorithmic tool. For example, ‘Department for Transport’. | The Cabinet Office |
| Team | Tier 2 - Owner and responsibility | The attribute ‘team’ is the full name of the team that carries responsibility for use of the algorithmic tool. | Digital Knowledge and Information Management Team |
| Senior responsible owner | Tier 2 - Owner and responsibility | The attribute ‘senior_responsible_owner’ is the role title of the senior responsible owner for the algorithmic tool. | Head of Digital Knowledge & Information Management |
| External supplier involvement | Tier 2 - Owner and Responsibility | Have external suppliers been involved in the development and operation of the tool? - Yes - No If yes: complete answers in the rest of section - If no: skip to section - |
Yes |
| Supplier or developer of the algorithmic tool | Tier 2 - Owner and responsibility | The attribute ‘supplier’ gives the name of any external organisation that has been contracted to develop the whole or parts of or the algorithmic tool. | Automated Intelligence Ltd |
| Companies House Number | Tier 2 - Owner and responsibility | The attribute ‘companies_house_number’ gives, if available, the Companies House number of the external organisation that has been contracted to develop either the whole, or a part of the algorithmic tool. You can find a company’s Companies House number by searching the Companies House register or using the Companies House API. If multiple organisations have been contracted, the Companies House Number for all of the companies should be provided, specifying which number represents which organisation. |
NI603151 |
| External supplier role | Tier 2 - Owner and responsibility | The attribute ‘external_supplier_role’ gives a short description of the role the external supplier had in the development of the algorithmic tool. If multiple organisations have been contracted or there are multiple companies involved in the delivery of the tool, these relationships should be described clearly and concisely. |
Automated Intelligence Ltd has supplied the software in which we programme our script and through which we operate our disposal methodology. This tool is a specialised elasticsearch based analysis platform called AI.Datalift. The tool provides visualisation of analysis and can be programmed to execute pre-set policy rules following analysis. It can identify sensitive information such as passport numbers, or addresses using artificial intelligence to assist analysts in understanding their unstructured data. |
| Procurement procedure type* | Tier 2 - Owner and responsibility | The attribute ‘procurment_procedure_type’ details the procurement procedure through which the contract has been set up. For example, ‘open’, ‘restricted’, or ‘competitive procedure with negotiation’, or ‘call-off from a dynamic purchasing system’, and ‘call-off from a framework’ where a contracting authority has awarded to a supplier under a pre-established framework agreement. |
Call off from a G Cloud framework |
| Terms of access to data for external supplier* | Tier 2 - Owner and responsibility | The attribute ‘data_access_terms’ details the terms of access to (government) data granted to the external supplier. | The supplier gains access to the data via a web crawler that makes an exact copy in the supplier’s system, where it can be subjected to analysis and treatment. The Authority (the Cabinet Office) requires the Supplier (Automated Intelligence Ltd) to provide the following products and services : - Data analytics tool that is programmable so that data can be classified as either ROT (Redundant, Outdated or Trivial) or as valuable - Data analytics tool that is able to action a deletion on data so designated. - Data analytics tool that is capable of classifying and searching data according to: - Date of creation - Date last modified - Date last accessed - File format - Keywords (exact phrase or with Boolean operators applied) - Duplicates / de-duplication - And a matrix of any or all of the above in combination- Data analytics tool that can assist with content analysis of documents and be able to present: - A list of the documents discovered - The metadata of the documents - Where keyword search is used, a view of the actual document discovered - Data visualisations of queries, showing volume against the parameters of queries applied. - Data analytics tool that can integrate and sync with CO systems for ongoing analysis (firstly in a Google environment, but not limited to) The following technical standards must also be upheld: - Minimum Cyber Security Standard - ISO/IEC 27001 - NCSC Cloud Security Principles - Cyber Essentials Plus and included within the service description provided under the relevant service ID. In addition, the following standards should be adhered to to the extent they are appropriate and agreed as such by both parties, such agreement to be reached within a reasonable period of being under contract): - Digital Service Standard - Technology Code of Practice - Web Content Accessibility Guidelines with conformance not below level AA. |
| Detailed description | Tier 2 - Detailed Description and Rationale | The attribute ‘detailed_description’ gives a detailed description of how the algorithmic tool works. Compared to the high-level description in Tier 1, the detailed description should provide an explanation at a more granular and technical level, including the main rules and criteria used by the algorithm/algorithms. This field is optional and is very likely to include information required in other fields below. It is open to the organisation to decide whether they want to include a summary detailed description in addition to the information below. |
The algorithm provides a means to automate the analysis of high volumes of digital information so that records of historic or corporate value can be retained and redundant, outdated and trivial information deleted. We have developed an understanding of the key-words or phrases commonly used by civil servants in documents that are recognised as important records. Conversely, patterns of language can be constructed that are commonly found in redundant, outdated and trivial information (known as ‘R.O.T.’) which is of little or no value. These words or phrases (also known as ‘terms’) can be identified in documents using search engines. The words or phrases identified are collated into a list called ‘The Lexicon.’ Terms in the Lexicon are weighted (i.e. given a value) so that when the search engine discovers a term in a document it is able to determine its value as a historic record. The Model When the algorithm is applied to a collection of digital documents, the following categories are defined: - File extension types split into: a. File extension types that are weighted towards retention; b. File extension types that are weighted towards deletion; c. File extension types that are indexable (i.e. capable of being read); d. File extension types that are not indexable; - Documents where the lexicon terms is indicating historic value. - Documents where the lexicon terms is indicating ROT. - Documents where the lexicon of terms is indicating both ROT and value terms. To illustrate where these parameters fit into the model, Figure A gives a visual representation of how each of the six classifications are applied and demonstrates how 1a and 1b (categorising file extensions) divide and treat files differently. See Figure 1 for the Flowchart of Backend of Lexicon Decision Making The file types that are most likely to contain information of historic value must contain more lexicon terms that indicate R.O.T. than default delete files in order to be put into a deletion classification. This is because through the collective experience of records management professionals combined with dip sampling data, we know that the proportion of documents that fall into the default retain file types generally have a prevalence of valuable files of c.15%+, whilst for those that fall into the default delete types the prevalence of valuable files is between zero and 1%. It is important to emphasise that the file type only contributes to how the full lexicon of terms is applied and it is still the frequency and type of terms that arise in the files and their metadata that determine whether deletion or retention is recommended by the algorithm. The only exception to this is .pst files which are always retained. A detailed breakdown of the characteristics of files in each classification and an example of a typical file that would fall into each one is provided below. Note: Wildcard Definition A wildcard is a special character that can stand in for unknown characters in a text value. If a file’s content is not a wildcard then it has no indexable content i.e. no words detected inside. If the file content is not a wildcard but the extension type should be indexable, we know the file does not contain useful information. Classification A: Size of Zero - Size zero files that are completely empty. (Example of this type of file: completely empty file or any extension type.) Classification B: Empty - File content is not a wildcard. - File content is indexable file type and therefore contains no content. - The file is not a .pst. (Example of this type of file: a word document with no content except one space character.) Classification C: Not Indexable Default retain deletions - File content is not a wildcard. - File extension is not indexable (NOT doc, txt, docx, msg etc.) - The file is not .pst. - File extension IS one of the default retain (eg pdf, jpg, tif, tiff) - Filename & Path Analysis: No value terms picked up AND at least one ROT term picked up (Example of this type of file: a pdf with the file title: ‘RE inv: August workshop’) Classification D: Not Indexable Default delete Deletions - File content is not a wildcard. - The file is not .pst. - File extension is not indexable (NOT doc, txt, docx, msg etc.) - File extension IS one of the default delete (eg ico, wp, sql) - Filename & Path Analysis: No value terms picked up OR a ROT term picked up (Example of this type of file: SQL database file with file title: ‘dneowfjeiofsnco238fekrn34’) Classification E: Indexable default retain for deletion - The file is not .pst. - File extension is indexable (doc, txt, docx, msg etc.) - File extension IS one of the default retain (eg pdf, jpg, tif, tiff) - Filename & Path Analysis: No value terms picked up AND at least one ROT term picked up (Example of this type of file: an email .msg file containing no value terms and the terms: ‘admin’, ‘stuff’ and ‘template’.) Classification F: Indexable Default delete for deletion - The file is not .pst. - File extension is indexable (doc, txt, docx, msg etc.) - File extension IS one of the default delete (eg. ico, wp, sql) - Filename & Path Analysis: No value terms picked up (Example of this type of file: a webpage with no value terms in the content, title or filepath.) |
| Scope | Tier 2 - Detailed Description and Rationale | The attribute ‘scope’ describes the purpose of the tool in terms of what it has been designed for and what it has not been designed for. This can include a list of potential purposes that the tool was not designed for: this can help to avoid misconceptions about the scope and purpose of the tool. |
The methodology, the algorithm and the lexicon have been created to ease the burden on archivists and records managers by automating part of the repetitive decision making process of identifying files suitable for retention as part of a disposal operation. The algorithm is intended to be applied to collections held by the Cabinet Office (or any other organisation) for the purposes of identifying files to dispose of in line with the organisation’s destruction and retention policy. The algorithm is designed for use on such collections where: - There is a suspected mixture of both R.O.T. (Redundant, Obsolete or Trivial) files and files of historic value that must be retained. - The collection is too large to identify which files to dispose of and retain manually. - A small risk tolerance for files of historic value being incorrectly disposed of is acceptable. - It is acceptable to create a temporary copy of the files in the Automated Intelligence tool AI Datalift in order to conduct the analysis. If the collection meets these requirements then automating disposal via the lexicon methodology using the algorithm may be a sensible option. The algorithm is not intended to be used as part of a sensitivity review process. |
| Benefit | Tier 2 - Detailed Description and Rationale | The attribute ‘benefit’ describes the key benefits that the algorithmic tool is expected to deliver, and an expanded justification of why the tool is being used. | The benefits of using the Lexicon model to automate digital information disposal include: - Efficiency/cost avoidance: the algorithm and overall methodology automates previously manual processes that, in the context of digital records management, are no longer a viable or sustainable approach. - Consistency and accuracy: automation is consistently more accurate than humans at making decisions about the records value of a document; our tests showed that human error was ~1% but the automation showed an error rate likely to be < 0.6%. - Speed: We estimate that a human reviewer could reasonably review up to 200,000 documents per annum. With automation we could achieve a review of several million files with no increase in human resource required to accommodate the higher volumes of files to be reviewed. |
| Previous process | Tier 2 - Detailed Description and Rationale | The attribute ‘previous_process’ gives a description of the decision making process that took place prior to the deployment of the tool, where applicable. | The previous method of disposal before the creation of the lexicon model consisted of digital archivists manually reviewing files both at a folder level and individual file level. This method was fairly accurate but extremely slow compared with our now automated solution, and was exclusively carried out using paper documents. Review of digital documents had not previously been attempted at scale. The human reviewers would take into account the content of the documents and make a decision as to whether the file should be disposed of or retained and reviewed again at a later date. Even with expert reviewers applying the destruction and retention policy to the best of their ability this process of manual review was sometimes subjective. Also, in many cases, no records were kept of the reasons for destruction decisions and the error rate was therefore unknown. The process of human review is very slow compared with the automated approach. |
| Alternatives considered | Tier 2 - Detailed Description and Rationale | The attribute ‘alternatives_considered’ details, where applicable, a list of other algorithmic and non-algorithmic alternatives considered. It should explain why a certain algorithmic approach was chosen over other approaches, and why the chosen tool is the best available option given any known risks and shortcomings and trade-offs. |
Machine Learning An approach applying machine learning was considered. However, we did not possess a large enough labelled training dataset to make supervised ML a viable option. An unsupervised learning model such as a clustering machine learning algorithm could have aided in categorising documents into different groups but would not have been able to distinguish which of those clusters should be put forward for retention or deletion. Another reason this approach would have been difficult to implement is a lack of expertise and skills in this area within the existing team and headcount restrictions. |
| Process integration | Tier 2 - Decision-making Process | The attribute ‘process_integration’ explains how the algorithmic tool is integrated into the decision-making process and what influence the algorithmic tool has on the decision-making process. It gives a more detailed and extensive description of the wider decision-making process into which the algorithmic tool is embedded. | Our digital disposal system ingests usually unstructured legacy files from business units and applies the disposal process. This results in a smaller number of historically relevant files that can be moved to our Cabinet Office archive and eventually to The National Archives. See Figure 2 for a schematic of the Cabinet Office digital disposal filtration process. The algorithm is applied using the lexicon at the ‘aggressive reduction stage of our disposal process. |
| Provided information | Tier 2 - Decision-making Process | The attribute ‘provided information’ details how much and what information the algorithmic tool provides to the decision maker. For example, this can include the prediction output and the form in which it is presented to the decision maker. This field should also detail any internal procedures that are in place to document the relationship between the output and the decision. Such procedures should, where applicable, include information on the extent to which decisions have been influenced by the tool. |
The output of the tool is a report detailing the recommended files to be deleted. A digital archivist can review this report, analyse and test the final results to ensure the application of the lexicon on the collection is in-line with the standards agreed by Departmental Governance, which is that less than 1% of files are incorrectly identified for deletion. Details of what files have been deleted should be added to the deletions report and emailed permission should be obtained from the DRO prior to actioning these deletions. Alongside the deletions report a copy of the elasticsearch code should be saved to ensure a record and logical reasoning for why deletions have been actioned is preserved for any future audits. |
| Human decisions and review | Tier 2 - Decision-making Process | The attribute ‘human_decisions_and_review’ describes the decisions that people take in the overall process. It should also detail human review options. For example, specific details on when and how a person reviews or checks the automated decision. | The decisions required to be made by humans include: - Judging that the collection is suitable for the application of the lexicon to it, this involves verifying that: - There is a suspected mixture of both ROT (Redundant, Obsolete or Trivial) files and files of historic value that must be retained. - The collection is too large to identify which files to dispose of and retain manually. - A small risk tolerance for files of historic value being incorrectly disposed of is acceptable. - It is acceptable to create a temporary copy of the files in the technology tool in order to conduct the analysis. - Reviewing the search terms used within the lexicon and conducting sense-checking tests to ensure the terms used are not returning anomalous results. This is because all collections are different and use of certain language changes over time. A term that significantly increases the likelihood that a document is valuable in documents created in 2005 does not always have the same result on files created in 2022. - Ensuring the algorithm is performing to the minimum acceptable level as approved by departmental governance, which is 1% or less of files reviewed are incorrectly identified for destruction. |
| Required training | Tier 2 - Decision-making Process | The attribute ‘required_training’ details the required training those deploying or using the algorithmic tool must undertake, if applicable. This can include training for operations, users, maintenance, compliance, or oversight personnel. For example, the person responsible for the management of the tool had to complete data science training. |
The Data Analyst completed a Data Science 3 month intensive bootcamp and ElasticSearch training courses to upskill in Python (required for data cleaning and analysis of test results) and ElasticSearch (the language the lexicon is programmed in). All team members involved with the project attended learning sessions hosted by the supplier of the data classification tool used to run the algorithm in which they learned how to operate the in-built analysis tool. |
| Appeals and review | Tier 2 - Decision-making Process | The attribute ‘appeals_and_review’ details the mechanisms that are in place for review or appeal of the decision available to the general public, where applicable. | Once a destruction decision has been made and a file deleted, this is a hard deletion and therefore by definition the file is non-recoverable meaning an appeal is not possible. The elasticsearch code and all terms within the lexicon will be saved along with the deletions record so in the case of an appeal or Freedom of Information Act request we could provide justification as to why a certain file was deleted. |
| Method | Tier 2 - Technical Specification and Data | The attribute ‘method’ indicates which types of methods or models the algorithm is using. For example, linear regression, expert system, different kinds of machine learning algorithms, and so on. This can also include a short description of the method(s) used and/or a link to resources providing further resources on the method(s). |
The method used is a deterministic automated language model. The method is a scoring system using ElasticSearch which assigns a relevancy score to each file based on: Term Frequency How many times a term is present in a document or document metadata such as filename and filepath. The more times a term appears, the more relevant the document is. In this case, the relevancy is how likely the file is redundant, obsolete or trivial and therefore should be deleted. Inverse Document Frequency The more documents in the collection the lexicon is run over that contain a term, the less important and impactful it is. For example if we put the term ‘the’ into the lexicon it would not have any notifiable impact because virtually every document will contain the word ‘the’. This feature protects the lexicon from certain types of bias, e.g. where common phrases, that add little or nothing to the calculation of the historic value of information, can be discounted. Field Length If many search terms appear in a very short document, then this document has a high density of terms and this is treated as more significant than a 5000 word document with the same number of search terms inside. This also weights the appearance of search terms inside filenames as a stronger indicator as the field length of document titles tend to be shorter than the contents of documents. These components contribute to the overall relevancy score assigned to files. Each file receives this score and then a threshold is decided based on review and dip sampling of files with varying relevance scores. Decisions of this threshold are reviewed on a collection basis with the aim to minimise the number of files incorrectly deleted. |
| Frequency and scale of usage | Tier 2 - Technical Specification and Data | The attribute ‘frequency_and_scale_of_usage’ gives information on how regularly the algorithmic tool is being used and the scale of use. For example, the number of decisions made per month, the number of citizens interacting with the tool, and so on. |
The algorithm has been used to review 5.1 million legacy files to date. The team is currently using their disposal methodology to review a further ~300,000 files which will be completed in this financial year (2023/24). After this time, the algorithm will be used on an annual basis to review the stream of files surrendered to the Digital Knowledge and Information Management team from Business Units. The number of files received in the future is unknown but is likely to be approximately 30,000-80,000 files per year. |
| Phase | Tier 2 - Technical Specification and Data | The attribute ‘phase’ indicates in which of the following stages or phases the tool is currently in: - Production - Idea - Design - Development - Beta/Pilot - Production - Retired This field includes date and time stamps of creation and any updates. |
Production The methodology, which includes the algorithm and lexicon, was created over a period of months from January 2022 to June 2022. The lexicon was approved for use on legacy Cabinet Office files by departmental governance on the 30th June 2022. The first lexicon/algorithm informed deletions took place on the 22nd July 2022 and consisted of the permanent destruction of 1,663,180 files that were acknowledged as Redundant, Outdated or Trivial (ROT) deletions. |
| Maintenance | Tier 2 - Technical Specification and Data | The attribute ‘maintenance’ gives details on the maintenance schedule and frequency of any reviews. This includes information such as how often and in what way the tool is being reviewed post-deployment, and how it is being maintained if further development is needed. This can concern maintenance both by the supplier as well as by the operator/user of the tool. |
The Lexicon requires ‘tuning’ when applied to a new collection of files. This is because all collections are different and use of certain language changes over time. A term that significantly increases the likelihood that a document is valuable in documents created in 2005 does not always have the same result on files created in 2023. The frequency of the tuning of the lexicon is dependent on how many different collections the DKIM Lifecycle team analyse but there will be a minimum of an annual review. This relates to the frequency of the annual ‘Spring Clean,’ an acquisition process that involves the transfer of documents older than 7 years from all business units to the DKIM. The intention is to use the lexicon to aid the digital archivists in the review of these transfers once all legacy datasets have been analysed. |
| Model performance | Tier 2 - Technical Specification and Data | The attribute ‘model_performance’ gives details on the model or tool’s performance. Useful metrics to consider are: accuracy metrics (such as precision, recall, F1 scores), metrics related to privacy, and metrics related to computational efficiency. It also gives details on any identified biases in the data and model. If applicable, it describes how bias and accuracy have been balanced in the model. |
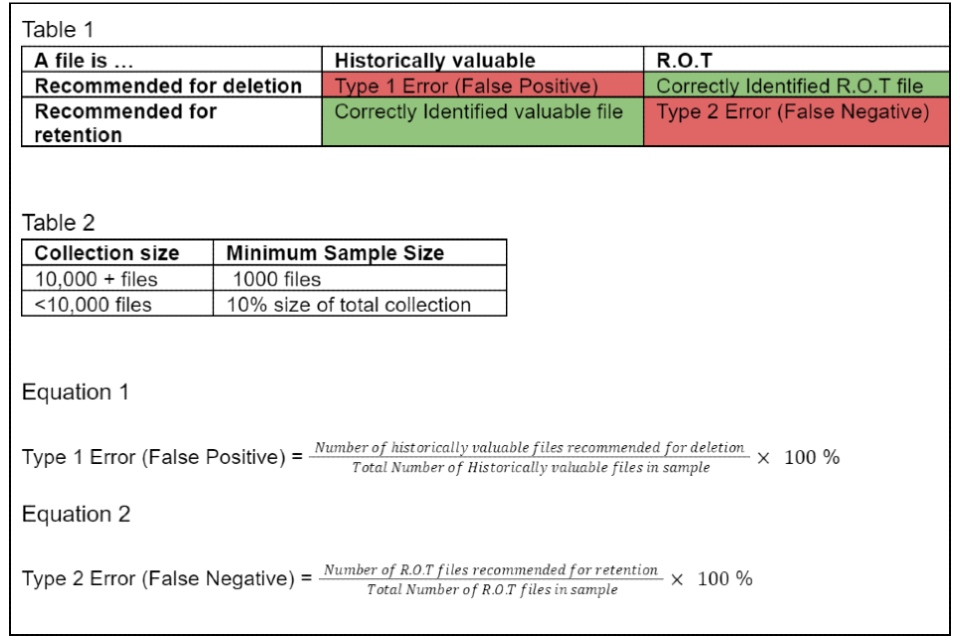
Testing Method In the pilot, the method used to test how effective the lexicon was at correctly identifying files to dispose of and files to keep, was by creating a random sample of labelled files from the collection and then applying the lexicon to them. The percentage of files incorrectly identified was the estimate for the error rates of the model. Types of Error Rates and How to Calculate Them There are two types of error the lexicon can make: incorrectly recommending the destruction of a file that should be retained (Type 1 error, a false positive) and incorrectly recommending the retention of a file that we could dispose of (Type 2 error, a false negative). See Table 1 in Figure 3 for error descriptions. Sample Size A good rule of thumb for dip sampling a statistically significant number of files is either 10% of the total number of files in the collection or if the collection is so large that sampling that many files is unfeasible, 1000 randomly sampled files can be used. If there is bandwidth to do so then increasing the sample size would be likely to produce a more accurate estimate of the error rates, which would be preferable. See Table 2 in Figure 3 for sample size criteria. Success criteria The purpose of producing the estimates for how effective the version of the lexicon used is on the collection in question is ultimately to see whether the model can be used. The following levels of success criteria were agreed upon by departmental governance. Type 1 Error Success criteria with regards to over deletion (deleting files of historic value that should have been retained) was approved by departmental governance . The value must fall below 1%. If the type 1 error rate is higher than this, the lexicon must be tuned further. See Equation 1 in Figure 3 for Type 1 Error calculation. Type 2 Error The acceptable level of under deletion (retaining files that are redundant, obsolete or Trivial is dependent on the collection and results. No exact figure has been agreed by a governing body. The type 2 error needs to be risk assessed per collection and version of the lexicon, taking into account the proportion of value suspected in the collection and how valuable this is likely to be. This will also vary per collection as there will be varying proportions of value and ROT files in different collections. See Equation 2 in Figure 3 for Type 2 Error calculation. Relationship between Type 1 and Type 2 Error There will usually be an inverse relationship between the Type 1 and Type 2 error rates. The more cautious a model is at recommending disposal, the smaller the type 1 error will be, but this will increase the Type 2 error. |
| System architecture | Tier 2 - Technical Specification and Data | The attribute ‘system_architecture’ is the URL reference to documentation about the system architecture. For example, a link to a GitHub repository image or additional documentation about the system architecture. | N/A |
| Source data name | Tier 2 - Technical Specification and Data | The attribute ‘source_data_name’ gives, if applicable, the name of the datasets used. | N/A |
| Source data description |
Tier 2 - Technical Specification and Data | The attribute ‘source_data_description’ gives an overview of the data used to train, test, configure and operate the algorithmic tool, specifying which data was used for which purpose. This should encompass data used by both the public sector team and the supplier, where applicable. It should include a description of the types of variables or features used to train, test or run the model - for example ‘age’ or ‘address’. In certain cases, it might not be feasible for a team to disclose all the variables in a dataset. In this case, teams should disclose - at a minimum: whether the data contains personal and special category information; variables of interest, such as protected characteristics and potential proxies; and variables with high predictive power or that have a significant bearing on the model. |
The source data consists of unstructured data surrendered to the DKIM team from CO business units. The data classification tool used to deploy the algorithm extracts the following information from the unstructured data in order to run the lexicon model: - File title - Historical file path (if available) - File content (if indexable - eg. an image file contains no words so field is blank) - File creation date - File last modified date - File mimetype - File extension type |
| Source data URL | Tier 2 - Technical Specification and Data | The attribute ‘source_data_url’ provides a URL to the openly accessible dataset wherever possible. | N/A |
| Data collection | Tier 2 - Technical Specification and Data | The attribute ‘data_collection’ gives information on the data collection process. This can include details on the original purpose of data collection and the context in which it was initially collected. If the data was initially collected for different purposes and is now being repurposed, there should be consideration of to what extent the data transferable and suitable for the new context. |
Legacy documents from business units are acquired by the DKIM Team so that they can ensure compliance with the Public Records Act 1958. |
| Data cleaning | Tier 2 - Technical Specification and Data | The attribute ‘data_cleaning’ gives information on data cleaning, including a description of any pre-processing or cleaning of the data conducted by either the supplier or public sector customer. | The following fields are extracted from the unstructured data (files): - File title - Historical file path (if available) - File content (if indexable - eg. an image file contains no words so field is blank) - File creation date - File last modified date - File mimetype - File extension type Data cleaning techniques such as removing any outlier files from the review or handling missing data is not applicable. The data classification tool used to run the algorithm detects whether a file has missing metadata such as being non-indexable eg. an image or video file and treats these accordingly. Prior to running the algorithm, the archivists will prepare the data set through removing any obvious areas of ROT through a high level review. The archivists utilise the department’s Records Selection Policy to identify themes in the collection that are either required to be retained or not. |
| Data completeness and representativeness | Tier 2 - Technical Specification and Data | The attribute ‘data_completeness_and_representativeness’ provides information on the completeness of the data, including missing data and on how representative the data is. | As the nature of the problem is to make decisions based on all files the process is able to handle a variety of different scenarios including missing or corrupted data just like a human reviewer would. The goal of the creation of the lexicon is to mimic the decision of an expert reviewer, who would always seek to make the best decision possible with the information available. As there are generally no files with missing file names or file paths, the only ‘missing data’ to handle is file content. File content In the absence of file content the algorithm will identify that file for deletion where the size of the file is zero. This is because a file with no content does not contain any useful information and therefore does not need to be retained. |
| Data sharing agreements | Tier 2 - Technical Specification and Data | The attribute ‘data_sharing_agreements’ provides further information on data sharing agreements in place. | No data sharing agreements are in place beyond commercial contracts. |
| Data access and storage | Tier 2 - Technical Specification and Data | The attribute ‘data_access_and_storage’ details: who has, or will have, access to this data; how long it is stored; under what circumstances; and who is responsible for its storage. Where personal and/or sensitive data is being stored and accessed, a description of the mechanisms used to protect the security and privacy of the data should be described, including technical (e.g. de-identification techniques, Privacy Enhancing Technologies) and operational (e.g. role-based access controls) methods. |
A temporary copy of personal data is made in order to enable the analysis of files. Once the analysis is completed a hard deletion of this temporary copy is actioned. This means the files from that copy are not retrievable after the conclusion of analysis. One of the goals of the use of the system is to enable identification of personal data that is not required to be retained as part of the official record, so that files containing personal data that should be removed are not retained in the Cabinet Office archive. Only members of the DKIM team that require access to the tool AI Datalift are granted an administrator account with access to the information being analysed. Team members hold appropriate security clearances. |
| Impact assessment | Tier 2 - Risks, mitigations and impact assessments | The attribute ‘impact_assessments’ provides the names and a short overview of the impact assessments conducted, date of completion, and if possible a summary of the findings. If available, a publicly accessible link should be provided. If multiple impact assessments were completed, they should all be listed in this field. Examples of impact assessments are Data Protection Impact Assessments (DPIAs), Equality Impact Assessments, Algorithmic Impact Assessments. This field also provides an opportunity to list other monitoring and evaluation requirements under relevant legislation. |
A DPIA was completed on 14th June 2023 Summary:The risk rating is Medium. The residual risk is considered LOW. There are a number of risk mitigations in place for this process. Each of them are designed to limit the potential of negative impacts on the processing of the data. Despite the lack of clarity of the potential of the inclusion of special categories of data, the process is compliant and within the expectations of the public. Also the technical and organisational controls strictly limit the potential risks As a consequence the residual risk is considered LOW. The risk of over retention of personal data is possible but unlikely as obvious collections of personal data (e.g. HR files) will have been sifted out in the preparation phase of each disposal. As the purpose of the algorithm is to identify records of value for long term preservation, the archiving of personal data in the public interest is accepted within the GDPR as legitimate. |
| Risks | Tier 2 - Risks, mitigations and impact assessments | The attribute ‘risks’ is an overview and a description of the possible risks that have been identified for the algorithmic tool. It also gives an overview of how the risks have been mitigated. |
The challenges of using automation in this space are: - Transparency - automation processes need to be understandable, with a clearly agreed margin for error. We have therefore engaged in peer review through discussing our approach with The National Archives, who are supportive. Our automation pilot achieved an accuracy rate of at least 99.4%, which proved to be better than a manual review process. - Trust - any automated approach needs to be demonstrably trustworthy in arriving at consistently good outcomes. It is important to note therefore that retention and deletion ultimately remains a human decision and are not automated, but the automation produces fast analysis and visualisation to allow human decision making to take place at scale and at pace. - Repeatability - While the lexicon based approach allows us to repeat the same methodology in any information collection, we are aware that all collections usually have some unique characteristics. Consequently our processes will dictate that before the automation can be applied to a collection, it must be ‘tuned’ following a scoping exercise carried out by our team of expert digital archivists. - There is a risk that running the algorithm results in either the destruction of important records or retention of ROT. This risk can be mitigated by: - Setting an organisational risk appetite. Cabinet Office’s modelling demonstrated that an accuracy rate of at least 99.4% could be achieved, which is better than the performance of comparative human models; - Modelling and testing prior to disposal to ensure that the terms in the lexicon are valid and correctly weighted; In Cabinet Office this involves running a test review and measuring how close the outcome is to the 99.4% baseline; - Weighting terms in the lexicon: this will depend on the risk appetite of the individual organisation. A risk averse organisation may place more emphasis on weighting in order to resolve ‘grey areas.’ |
- Figure 1: A flowchart of the backend of Lexicon decision-making.
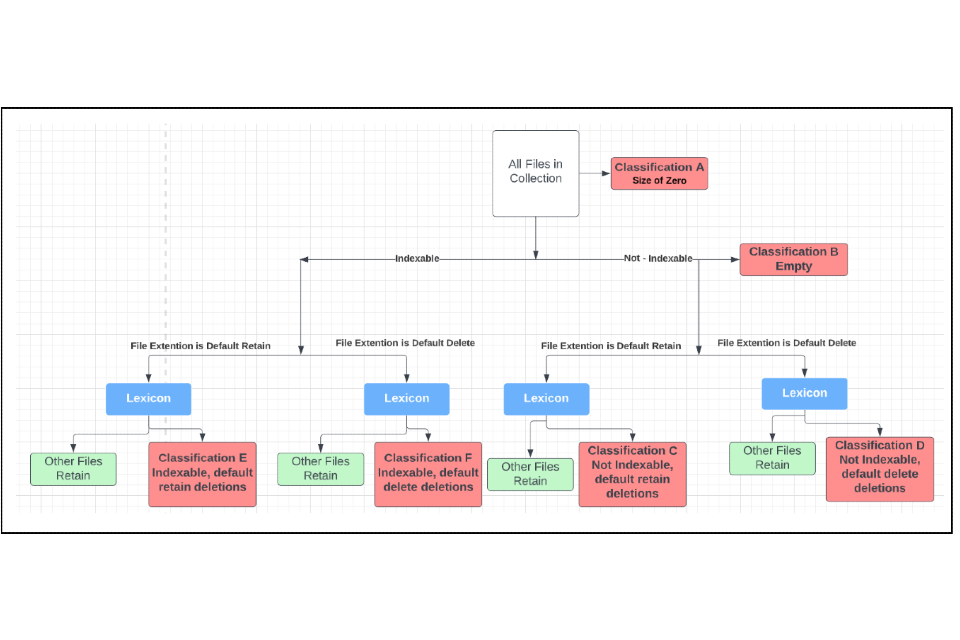
- Figure 2: A schematic of the digital disposal filtration process.
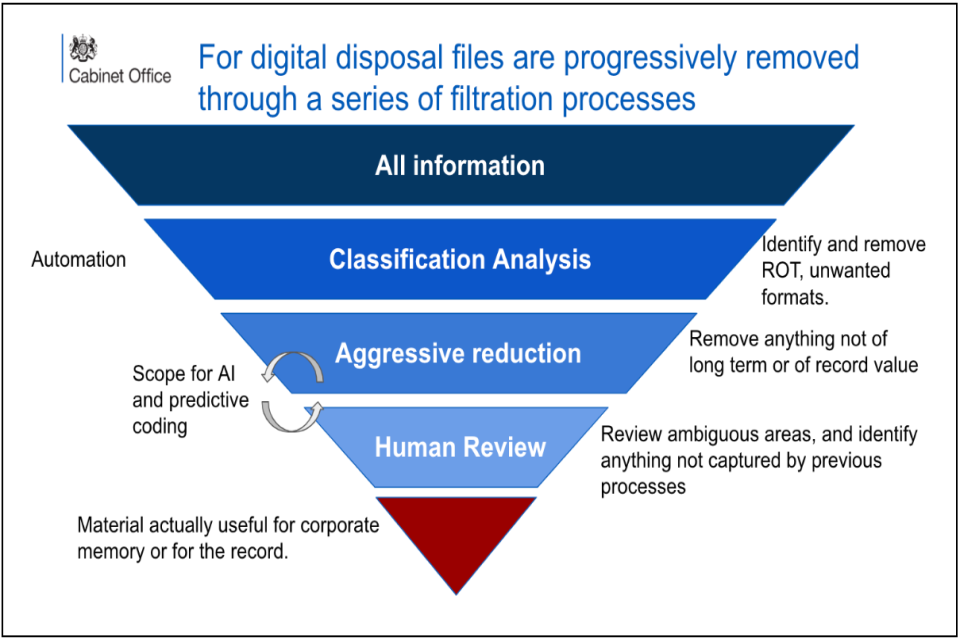
- Figure 3: Sample size criteria and error calculations.