Tax gaps: Methodological annex
Updated 19 June 2025

© Crown copyright 2025
This publication is licensed under the terms of the Open Government Licence v3.0 except where otherwise stated. To view this licence, visit nationalarchives.gov.uk/doc/open-government-licence/version/3 or write to the Information Policy Team, The National Archives, Kew, London TW9 4DU, or email: psi@nationalarchives.gov.uk.
Where we have identified any third party copyright information you will need to obtain permission from the copyright holders concerned.
This publication is available at https://www.gov.uk/government/statistics/measuring-tax-gaps/methodological-annex
Chapter A: Introduction
Methodology
A1. This document provides further details of the data and methodology used to produce estimates of the tax gap published in ‘Measuring tax gaps 2025 edition’.
A2. There are numerous methodological approaches to measuring tax gaps. The tax gap is the difference between the amount of tax that should, in theory, be paid to HMRC (‘theoretical tax liability’), and the amount that is actually paid.
A3. Top-down methods use external independent data sources to estimate total consumption of taxable products to calculate the total theoretical liabilities. An example of this is the VAT gap.
A4. Bottom-up methods include a number of techniques:
- random enquiry programmes — these involve undertaking compliance checks for a randomly selected sample of customers and scaling up the findings from the sampled cases to the relevant whole population.
- statistical methods — unlike random enquiry programmes these use risk-based compliance checks that are not representative of the whole population, and require statistical methods to scale up the results to the whole population
- population surveys — we use results from a bespoke research survey to estimate part of the hidden economy tax gap
- management information — these methods use management information such as:
- risk registers (a list of identified tax risks, together with information such as estimated value, nature and status)
- data extracted from accounting systems
- other databases or systems used to manage HMRC’s business
A5. The total tax gap is estimated using established statistical and illustrative methods. Illustrative methodologies, formerly called experimental methodologies, are used to produce estimates where there is no direct measurement data. For these tax gap components, we use the best available data and simple models to build an estimate of the tax gap.
A6. We employ the most appropriate methodology for each tax gap component, based on the factors listed below:
- availability of quality HMRC data
- availability of quality independent data
- structure of the tax regime
- cost and impact for both HMRC and taxpayers
- level of granularity required
A7. Generally, following good international practice, we use ‘top-down’ methodologies for indirect taxes and ‘bottom-up’ methodologies for direct taxes. The tax gap estimates may, however, also be produced by compiling the results from a combination of two or more methods.
Methods used to estimate the tax gap
A8. Table A.1 below shows the general methodological approach used to estimate each tax gap component.
Table A.1 Tax gap methodologies
| Top-down | Bottom-up (management information) | Bottom-up (statistical and survey) | Bottom-up (random enquiries) | Illustrative |
|---|---|---|---|---|
| Alcohol duties | Alcohol duties | PAYE mid-sized businesses | PAYE small businesses | PAYE large businesses |
| VAT all businesses | Hidden economy | Hidden economy | SA business and non-business | SA large partnerships |
| Tobacco duties | — | CT mid-sized businesses | CT small businesses | Stamp taxes |
| — | — | CT large businesses | Diesel duties | Other excise |
| — | — | Inheritance Tax | — | Other remaining taxes |
| — | — | Avoidance | — | — |
Notes for Table A.1
-
Alcohol duty gaps are produced using both top-down and bottom-up methodologies.
-
Hidden economy tax gaps for ghosts and moonlighters are produced using bottom-up management information and bottom-up statistical and survey methodologies.
A9. Figure A.1 below shows a summary of the tax gap by methodology. A degree of assumption and judgement has been applied to attribute some elements of the tax gap to methodology types, especially where a combination of methods is used.
Figure A.1 Tax gap by methodology (£ billion)
| Methodology | Total |
|---|---|
| Bottom-up (management information) | 1.7 |
| Bottom-up (random enquiries) | 23.0 |
| Bottom-up (statistical and survey) | 5.1 |
| Illustrative | 5.9 |
| Top-down | 11.0 |
A10. Over time, we have tried to estimate more of the tax gap using an established top-down or bottom-up methodology and rely less on illustrative methods. This is difficult to show on a comparable basis as the tax gap for earlier years is often revised between editions either when methodological improvements are made or the underlying data is updated — and the overall value of the gap changes over time.
A11. Table A.2 sets out the proportions of the total tax gap classed as established or illustrative in the last 6 editions of ‘Measuring tax gaps’. This shows 87% of the tax gap is estimated using established methods in ‘Measuring tax gaps 2025 edition’ compared to 76% in the 2019 edition.
A12. The proportion of the tax gap based on established methodologies has increased from 86% to 87% since ‘Measuring tax gaps 2024 edition’.
Table A.2 Share of total tax gap by established and illustrative methodologies in ‘Measuring tax gaps’ editions
| Measuring tax gaps edition | Illustrative methodology | Established methodology |
|---|---|---|
| MTG19 | 24% | 76% |
| MTG20 | 15% | 85% |
| MTG21 | 14% | 86% |
| MTG22 | 21% | 79% |
| MTG23 | 16% | 84% |
| MTG24 | 14% | 86% |
| MTG25 | 13% | 87% |
Tax gap development programme
A13. As official statistics, our tax gap estimates are produced with the highest levels of quality assurance and adhere to the Code of Practice for Statistics framework. This code assures objectivity and integrity — providing the framework to ensure that statistics are trustworthy, good quality, and valuable. It also provides producers of official statistics with the detailed practices they must commit to when producing and releasing official statistics.
A14. To ensure our statistics continue to be trustworthy, good quality and valuable we have a continuous development programme. As part of this we publish:
- a summary of the improvements to the estimates introduced in the current edition of ‘Measuring tax gaps’ publication
- a high-level summary of development priorities to improve the tax gap estimates in future editions of the ‘Measuring tax gaps’ publication.
A15. HMRC have a continuous programme of development to improve and strengthen our tax gap estimates. However, not all tax gap methodologies can be improved due to limited data availability and the balancing of costs to produce the data against the value they add to the estimates. HMRC has limited resource to produce statistics. We also have to maintain and assure the quality of existing estimates, including when there are changes to data sources.
A16. The following list provides a summary of methodological and data improvements introduced in ‘Measuring tax gaps 2025 edition’.
-
An improvement to the methodology used to estimate the non-payment tax gap for Corporation Tax, and Income Tax, NICs, and Capital Gains Tax in Self Assessment and PAYE, for tax years since 2018 to 2019. The new methodology is an estimate of eventual non-payment attributable to the year of tax debt creation. This aligns to the VAT non-payment methodology introduced in ‘Measuring tax gaps 2023 edition’.
-
A new established methodology to estimate the tax gap for avoidance in Income Tax, NICs, and Capital Gains Tax for tax years since 2014 to 2015.
-
An improvement to the methodology used to forecast compliance yield from open cases for the large businesses Corporation Tax gap estimate.
A17. ‘In Measuring tax gaps editions’ 2022 and 2023, HMRC announced that it would be publishing an estimate of the tax gap arising from non-compliance by UK residents failing to declare their offshore income where this had been identified through data received from other fiscal authorities through Automatic Exchange of Information. On 24 October 2024 HMRC published the first assessment of Undisclosed Foreign Income (UFI) in Self Assessment from UK residents in the tax year 2018 to 2019
Priorities ahead of ‘Measuring tax gaps 2026 edition’
A18. The following list provides a high-level summary of planned developments. Future dates are estimates and depend on resource availability. Priorities may change and not everything we try to develop will always succeed.
- Review the presentation of the information in the publication and consistency over time.
High-level summary of longer-term development priorities
-
Publish a stand-alone customs duty gap. HMRC continues to explore new approaches to develop a robust methodology as due to the inherent complexity of a customs tax gap multiple data elements need to be explored. Development of a customs duty gap is a priority for HMRC and it remains HMRC’s plan to publish a stand-alone customs duty gap in the future.
-
Assess the feasibility of extending the published estimate of the tax gap arising from undisclosed foreign income, including engaging with academics.
-
Improve the assessment of the tax gap arising from wealthy taxpayers.
Chapter B: Accuracy and reliability
B1. Our tax gap estimates are official statistics produced to the highest levels of quality and adhere to the UK Statistics Authority’s Code of Practice for Statistics framework. This framework ensures statistics are trustworthy, good quality, valuable and provides producers of official statistics with the detailed practices they must commit to when producing and releasing official statistics.
B2. A Measuring tax gaps quality report accompanies this statistical release, providing information about the quality of outputs as set out by the Code of Practice for Statistics.
B3. The figures presented in the ‘Measuring tax gaps 2025 edition’ are our best estimates based on the information available, but there are sources of uncertainty and potential error. For this reason, it is best to focus on the trend in the results rather than the absolute numbers when interpreting findings.
Accuracy
B4. Accuracy refers to the closeness of estimates to the true values they are intended to measure. Due to the methodologies used, uncertainty is an inherent aspect of all tax gap estimates. Uncertainty relates to a range of possible factors that can affect the accuracy of a statistic, including the impact of measurement or sampling error (related to sample surveys) and all other sources of bias and variance that exist in a data source.
Reliability
B5. Reliability refers to the closeness of estimated values with subsequent estimates. The methodologies used to estimate tax gaps are subject to regular review and can change from year to year due to improvements in methodologies and data updates. These can result in revisions to any of the previously published estimates. Estimates are made on a like-for-like basis each year to enable users to interpret trends. Where data sources change over time, every effort has been made to ensure consistency in the time series, but this is another potential source of uncertainty.
Uncertainty
B6. Statistical uncertainty is caused by two factors:
- sampling error — errors that arise because the estimates rely on information collected from a sample, rather than from the whole population; sampling error can lead to year-on-year fluctuations in the tax gap estimates that do not reflect true changes in the size of the tax gap
- bias or non-sampling error — systematic errors where the modelling assumptions or errors in the data lead to estimates that are consistently either too low or too high.
B7. Where possible, HMRC has estimated the likely impact of sampling errors by calculating statistical confidence intervals. These give margins of error within which we would expect the true value lies 95% of the time, if there were no systematic errors. They provide an indication of the extent to which changes in the estimates between years can be confidently interpreted as true changes. They do not take account of systematic errors that might lead the central estimate to be too low or too high over the whole series.
B8. Systematic error is less straightforward to deal with, as it is not defined by statistical assessments that allow for easy interpretation. In order to give an indication of the effect of these biases, HMRC presents the tax gaps for alcohol and tobacco as ranges. For beer and tobacco these are constructed as the range between upper and lower bounds, representing the degree of uncertainty associated with those systematic biases for which upper and lower bounds can be derived.
Tax gap uncertainty assessment
B9. To show the uncertainty of tax gap estimates in a systematic and transparent way, we assign an overall uncertainty rating for each tax gap component in Table 1.1 ranging from ‘very low’ to ‘very high’. Table B.1 provides a guide on the interpretation of the meaning of the overall uncertainty ratings.
Table B.1 Overall uncertainty rating guide
| Overall uncertainty rating | Meaning |
|---|---|
| Very low | Very high confidence that the estimate is close to the actual |
| Low | High confidence that the estimate is close to the actual |
| Medium | The estimate is likely to be close to the actual but there is a possibility that it is different |
| High | Low confidence that the estimate is close to the actual |
| Very high | Very low confidence in the estimate — the actual is likely to be markedly different |
B10. To determine the uncertainty ratings of each tax gap component, we assess the uncertainty arising from each of three sources: the model scope, the methodology used and the data underpinning the estimate.
B11. In assessing model scope, we evaluate each estimate’s methodology against relevant criteria including:
- capture of the appropriate tax base
- coverage of the entire potential taxpayer population within model scope
- accounting for all potential forms of non-compliance
- no overlap between any two components of the tax regime
Table B.2 provides a guide on the interpretation of the uncertainty rating for model scope.
| Overall uncertainty rating | Model scope |
|---|---|
| Very low | Accounts for whole potential tax base and population. Accounts for all potential forms of non-compliance. No overlap with other estimates. |
| Low | Accounts for the large majority of the tax base and population. Accounts for the large majority of potential forms of non-compliance. No overlap with other estimates. |
| Medium | Accounts for most of the tax base and population. Accounts for most potential forms of non-compliance. No overlap with other estimates. |
| High | Missing some of the tax base and population. Some forms of non-compliance are risks not being accounted for. Some potential for overlap with other estimates. |
| Very high | Almost all the tax base and population are missing and almost no risks are being accounted for. Likely overlap with other estimates. |
B12. In assessing the methodology used we assess each estimate’s methodology against relevant criteria including:
- complexity and challenges of the model including the quality and impact of assumptions
- bias in the method, sampling errors (related to sample surveys), or reliability issues
- model volatility, margin of error, ranges and confidence
- external risks that may affect the outcome but are not taken into consideration within the model
Table B.3 provides a guide on the interpretation of the uncertainty rating for methodology.
| Overall uncertainty rating | Model methodology |
|---|---|
| Very low | Few or no sensitive assumptions. It is logical and straight forward with no complex analytical challenges. Model risks are robustly mitigated. |
| Low | Some sensitive assumptions and the model is logical and straightforward with few complex analytical challenges. Model risks are mitigated. |
| Medium | Some sensitive assumptions and challenges. The model is analytically complex with multiple stages. Some external risks with most unlikely and with good risk mitigation. |
| High | Multiple sensitive and unverifiable assumptions. Model may be too analytically complex or simplistic. Many risks, some of which have weak mitigation in place. |
| Very high | Assumption based sensitive model, most of which are unverifiable. Many risks with no strong mitigation. |
B13. In assessing the data underpinning the estimate, for both HMRC and third-party data, we evaluate each estimate’s methodology against relevant criteria including:
- data suitability for purpose
- understanding of data
- sensitivity analysis
Table B.4 provides a guide to the interpretation of the uncertainty rating for data.
| Overall uncertainty rating | Model data |
|---|---|
| Very low | High quality and assured data used throughout (no projecting, no non-detection multiplier uplifts). Completely understood data and highly suitable for use in tax gaps. |
| Low | High quality data (small amount of unsensitive projecting/non-detection multiplier uplifts). Mostly understood data and suitable for use in tax gaps. |
| Medium | Not complete data (a lot of assumptions but all logical and verifiable). Some data not fully understood but still acceptable for use in tax gaps with some caveats. |
| High | Little suitable data and of poor quality. Most of the data is not properly understood, many caveats but no alternative. |
| Very high | No suitable data, what is available is not well understood and is of low quality. |
B14. Table B.5 below shows the uncertainty rating for the tax year 2023 to 2024 for each tax gap component; by model scope, methodology used and data underpinning the estimate, and overall uncertainty rating. The overall uncertainty rating takes into account the relative importance of each uncertainty source for each tax gap estimate component.
Table B.5: Tax gap model uncertainty ratings, 2023 to 2024
| Tax gap model | Scope | Methodology | Data | Overall uncertainty rating |
|---|---|---|---|---|
| Corporation Tax — mid-sized businesses | Low | Medium | Medium | Medium |
| Corporation Tax — small businesses | Low | Medium | Medium | Medium |
| Corporation Tax — large businesses | Low | Medium | Medium | Medium |
| Alcohol duties — spirits duties | Low | High | High | High |
| Tobacco duties — hand-rolling tobacco duty | Very Low | High | Very High | High |
| Hydrocarbon oils duty | Low | Medium | Medium | Medium |
| Alcohol duties — beer duty | Low | High | High | High |
| Other excise duties | Very high | High | High | Very high |
| Tobacco duties — cigarette duty | Very Low | High | Very High | High |
| Self Assessment — non-business taxpayers | Low | Medium | Medium | Medium |
| Self Assessment — business taxpayers | Low | Medium | Medium | Medium |
| PAYE — mid-sized business | High | Medium | Medium | Medium |
| PAYE — small business | High | Medium | Low | Medium |
| Self Assessment — large partnerships | Very high | Very high | High | Very high |
| Income Tax, NICs, CGT hidden economy — moonlighters | High | High | High | High |
| Income Tax, NICs, CGT hidden economy — ghosts | Very high | High | Very high | Very high |
| PAYE — large business | High | Very High | Very High | Very high |
| Income Tax, NICs, CGT — avoidance | High | High | High | High |
| Inheritance Tax | High | High | High | High |
| Other taxes, levies and duties | Very high | High | Very high | Very high |
| Landfill Tax | High | Very high | High | High |
| Stamp Duty Reserve Tax | High | Very high | Very high | Very high |
| Stamp Duty Land Tax | Medium | High | High | High |
| VAT | Very Low | Medium | High | Medium |
Notes for Table B.5
-
‘Other excise duties’ includes betting and gaming duties, cider and perry duties, spirit-based ready-to-drink duties and wine duties.
-
Ghosts are individuals whose entire income is unknown to HMRC.
-
Moonlighters are individuals who are known to HMRC in relation to part of their income but have other sources of income that HMRC does not know about.
-
‘Other taxes, levies and duties’ includes Aggregates Levy, Air Passenger Duty, Customs Duty, Climate Change Levy, Digital Services Tax, Insurance Premium Tax, Plastic Packaging Tax and Soft Drinks Industry Levy.
VAT
B15. The theoretical VAT liability and the top-down VAT gap derived from it are broad measures, subject to a degree of uncertainty. They are based on analysis of survey and other data and include several assumptions and adjustments which add both random and systematic variation to the estimates. There is also a small element of forecasting in some of the spending data, which introduces further variation.
B16. It is not possible to produce a precise confidence interval for the VAT revenue loss estimates. The theoretical VAT liability estimate is constructed largely from Office for National Statistics (ONS) National Accounts data which are derived, in the main, from sample surveys and are thus subject to both sampling and non-sampling errors. The ONS does not publish error margins for the relevant input series and so it is not possible to construct an estimate of the impact of these errors on the theoretical VAT liability.
B17. The VAT gap is updated and revised as and when new data become available, or new methodologies are developed. HMRC publishes a revised historical VAT gap series once a year in the ‘Measuring tax gaps’ publication, incorporating both new and updated data and methodological improvements together. The VAT gap preliminary estimate for tax year 2023 to 2024 was published at Autumn Budget 2024 and a second estimate was published alongside Spring Statement 2025.
Excise duties
Systematic biases
B18. Systematic biases are explicitly considered for beer and tobacco products, with results presented as a range to represent the degree of uncertainty. These ranges are discussed in Annex E for beer and Annex F for tobacco products.
B19. No account is presently made for systematic biases in the spirits and diesel estimates.
Random variation
B20. While the upper and lower estimates for beer and tobacco will contain random variation, the resulting confidence intervals are not shown in this document as these estimates are used to represent the uncertainty around our central estimate.
B21. For spirits, an assessment of the effect of random variation is included using error margins. These are estimated by combining the random errors (where available) from all data sources used to calculate total consumption. These approximate to 95% confidence intervals, which is standard across statistical analysis.
B22. For diesel, an assessment of the effect of random variation is included using the error margins resulting from the data used to estimate illicit consumption.
B23. The central estimate for spirits may not necessarily be halfway between the upper and lower bounds as these bounds are confidence intervals, which may not be symmetric about the central estimate. As we do not have appropriate confidence intervals for the beer or tobacco tax gaps, the central estimate is calculated as the mid-point between the upper and lower estimates.
Direct taxes
Systematic biases
B24. For direct tax gap estimates based on random enquiries, adjustments are made to account for under-declarations of liabilities that are not detected. More information about our approach to non-detection multipliers can be found in HMRC’s working paper ‘Non-detection multipliers for measuring tax gaps’. HMRC continues to undertake analysis to define suitable ranges for other systematic biases in the direct tax estimates.
B25. Direct tax gaps that rely on management information methods measure known components separately. There are also unknown factors that are not fully identified, leading to additional unmeasured losses.
Random variation
B26. Direct tax estimates derived from random enquiries will be subject to random sampling errors — 95% confidence intervals have been calculated for these estimates using standard statistical techniques. These are included as the upper and lower estimates for estimates derived from random enquiries, where the range has been adjusted for non-detection.
Chapter C: Tax gap and compliance yield
C1. Tax gap estimates are calculated net of compliance yield — that is, they reflect the tax gap remaining after HMRC compliance activity.
C2. The cash expected element of compliance yield represents additional tax liabilities due which arise from checks into past non-compliance. Cash expected is tax gap closing and is part of the tax gap calculation for some but not all of the tax gap components. Whilst the tax gap reflects a single tax year, some compliance cases can cover multiple tax years. As a result the year in which cash expected is generated and recorded as compliance yield (and paid) is not always the same as the year to which liabilities relate. Therefore, in a given tax gap year, it is possible that the amount of compliance yield HMRC secures might increase while the percentage tax gap remains unchanged.
C3. HMRC publishes a detailed breakdown of compliance revenues within HMRC’s annual report and accounts. This differs in coverage and timing from the compliance information presented in ‘Measuring tax gaps’. A technical note explains how the methodology for measuring compliance yield in HMRC’s annual report and accounts differs from the methodology for how compliance yield is reflected in the tax gap estimates.
C4. To estimate the tax gap, some methodologies specifically use the cash expected element of compliance yield in the tax gap calculation:
| Tax gap component | Compliance yield |
|---|---|
| Self Assessment | Deducted from gross tax gap; actual compliance yield series shown in Table 4.1 of ‘Measuring tax gaps 2025 edition’. |
| Self Assessment for business taxpayers | Deducted from gross tax gap; actual compliance yield series shown in Table 4.4 ‘Measuring tax gaps 2025 edition’. |
| Self Assessment for non-business taxpayers | Deducted from gross tax gap; actual compliance yield series shown in Table 4.6 ‘Measuring tax gaps 2025 edition’. |
| Self Assessment for large partnerships | Deducted from gross tax gap; actual compliance yield series shown in Table 4.8 ‘Measuring tax gaps 2025 edition’. |
| Self Assessment (excluding large partnerships) | Deducted from gross tax gap; actual compliance yield series shown in Table 4.9 of ‘Measuring tax gaps 2025edition’. |
| PAYE | Deducted from gross tax gap; actual compliance yield series shown in Table 4.11 of ‘Measuring tax gaps 2025 edition’. This will represent both actual compliance yield (for closed cases) and estimates of compliance yield (for tax cases which are still under enquiry). |
| PAYE (small businesses) | Deducted from gross tax gap; actual compliance yield series shown in Table 4.13 of ‘Measuring tax gaps 2025 edition’. |
| PAYE (mid-sized businesses) | Deducted from gross tax gap; actual compliance yield series shown in Table 4.15 of ‘Measuring tax gaps 2025 edition’. This will represent both actual compliance yield (for closed cases) and estimates of compliance yield (for tax cases which are still under enquiry). |
| PAYE (large businesses) | Deducted from gross tax gap; actual compliance yield series shown in Table 4.16 of ‘Measuring tax gaps 2025 edition’. |
| Corporation Tax | Deducted from gross tax gap; compliance yield series shown in Table 5.1 of ‘Measuring tax gaps 2025 edition’. This will represent both actual compliance yield (for closed cases) and estimates of compliance yield (for tax cases which are still under enquiry). |
| Corporation Tax (small businesses) | Deducted from gross tax gap; actual compliance yield series shown in Table 5.2 of ‘Measuring tax gaps 2025 edition’. |
| Corporation Tax (mid-sized businesses) | Deducted from gross tax gap; actual compliance yield series shown in Table 5.4 of ‘Measuring tax gaps 2025 edition’. This will represent both actual compliance yield (for closed cases) and estimates of compliance yield (for tax cases which are still under enquiry). |
| Corporation Tax (large businesses) | Deducted from gross tax gap; compliance yield series shown in Table 5.5 of ‘Measuring tax gaps 2025 edition’. This will represent both actual compliance yield (for closed cases) and estimates of compliance yield (for tax cases which are still under enquiry). |
| Diesel | Deducted from gross tax gap. |
| Landfill Tax | Deducted from gross tax gap. |
C5. There is a lag in finalising all enquiries relating to a year of liability and our general methodology reflects this. It estimates the value of non-compliance in the liabilities generated each year and subtracts the amount of compliance yield recovered by HMRC in the relevant year. This is a simplified method that does not attempt to assign compliance yield to the year in which the tax liability arose, and it works well when compliance yield from year to year is relatively constant.
C6. Compliance yield for Self Assessment was impacted by the COVID-19 pandemic in 2020 to 2021 and 2021 to 2022. To preserve validity of assumptions and consistency in the time series, we have adjusted the Self Assessment compliance yield; we allocate the drop in the amount of compliance yield in 2020 to 2021 and 2021 to 2022 and recovered by HMRC to the year of liability. This change is only applied to Self Assessment where there is a material difference on the estimates, and our underlying methodology remains the same. No further adjustments have been applied to compliance yield data for 2022 to 2023 onwards.
C7. For mid-sized businesses PAYE and for mid-sized businesses and large businesses Corporation Tax gaps the established bottom-up statistical methodologies assign compliance yield to the year of liability. As identified risks can take many years to resolve it is necessary to forecast the expected compliance yield from open cases.
C8. In the following components of the tax gap, we either use an estimate of compliance yield as part of the calculation or do not take into account compliance yield:
| Tax gap component | Compliance yield |
|---|---|
| Avoidance (Income Tax, NICs, and Capital Gains Tax) | Compliance yield for open cases is estimated from previous trends in compliance yield for closed cases. |
| Hidden economy — ghosts | Does not currently take account of compliance yield. |
| Hidden economy — moonlighters | Does not currently take account of compliance yield. |
C9. In the remaining components of the tax gap we use a top-down method of calculation, looking at the difference between total theoretical liabilities and tax receipts. Although compliance yield is not explicitly included in these calculations it is reflected as part of tax receipts:
| Tax gap component | Compliance yield |
|---|---|
| VAT | Not explicitly used; but is reflected in receipts. |
| Tobacco duties | Not explicitly used; but is reflected in receipts. |
| Beer and spirit duties | Not explicitly used; but is reflected in receipts. |
Chapter D: Value Added Tax
VAT gap
General methodology
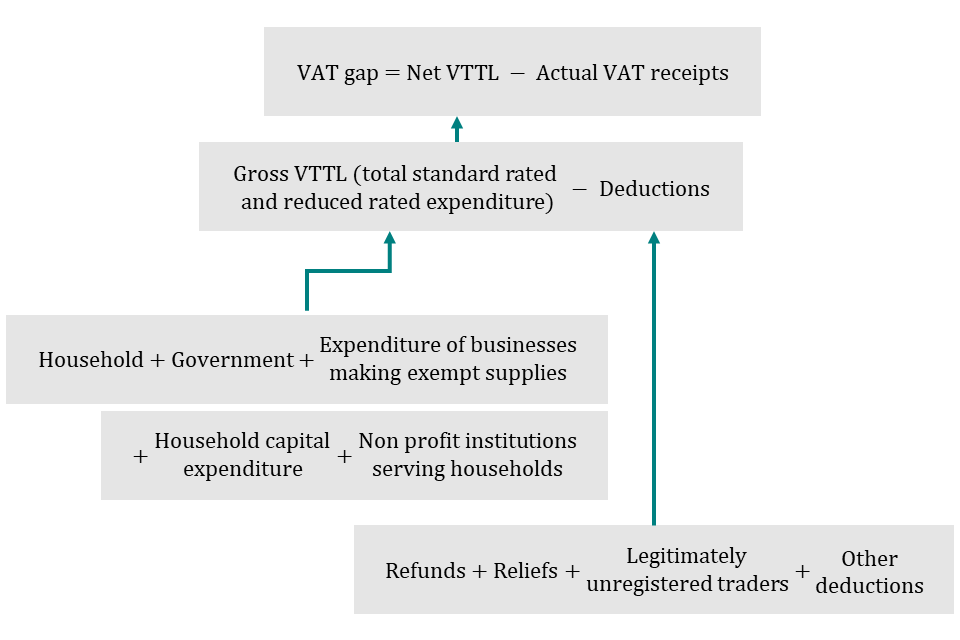
D1. The VAT gap is measured by estimating the total consumption of taxable goods and services to calculate the net VAT total theoretical liability; the VAT gap is the difference between the net VAT total theoretical liability and the VAT received. The VAT gap methodology uses a ‘top-down’ approach which involves:
- gathering data detailing the total amount of expenditure in the economy that is subject to VAT, primarily from the Office for National Statistics
- applying the rate of VAT on the Office for National Statistics’ expenditure data based on commodity breakdowns to derive the gross VAT total theoretical liability
- subtracting any legitimate refunds occurring through schemes and reliefs, to arrive at the net VAT total theoretical liability
- subtracting actual VAT receipts from the net VAT total theoretical liability
- leaving the residual element — the VAT gap, which includes, for example, error, evasion and debt
D2. The VAT total theoretical liability is the amount of VAT that should be collected in theory. This means applying the rate of VAT on that expenditure where VAT should be payable, assuming that there is no fraud, avoidance, or losses due to error or non-compliance.
D3. The VAT total theoretical liability includes irrecoverable VAT, which is the VAT paid on ‘finally taxed expenditure’ which cannot be reclaimed, for example by those not registered for VAT.
D4. The expenditure data series used in the calculation are mainly constituents of National Accounts macroeconomic aggregates. All National Accounts data used to construct VAT total theoretical liability estimates are consistent with the Office for National Statistics’s Blue Book 2024.
D5. More information about the consumer expenditure data sources can be found on the Office for National Statistics website.
Calculation of gross VAT total theoretical liability
D6. The gross VAT total theoretical liability is calculated by multiplying the total amount of expenditure in the economy (also known as VAT-able expenditure) by the appropriate VAT rates.
D7. For each of the expenditure sectors, the total expenditure is split according to the different VAT treatments: zero rated, standard rated, reduced rated, and exempt. For the purposes of calculating the gross VAT total theoretical liability, only the standard and reduced rated expenditure are used.
D8. There were COVID-19 policy measures introduced in 2020 to 2021 which changed the VAT treatments applied to particular types of expenditure. In 2020 to 2021, for example, a zero rate was applied to personal protective equipment expenditure aimed at helping to control the spread of coronavirus. In both 2020 to 2021 and 2021 to 2022 reduced rates were also applied to the hospitality sector, holiday accommodation and attractions. No COVID-19 policy measures were introduced beyond the financial year 2021 to 2022.
D9. The total VAT-able expenditure for each sector is combined to represent an overall annual figure for the economy.
D10. To derive the amount of VAT within the VAT-able expenditure, it is necessary to multiply the expenditure by the VAT fraction (the ratio of the VAT charged on the VAT-able expenditure to the total expenditure). The annual gross VAT total theoretical liability is therefore calculated by multiplying the annual expenditure figure for the economy by the respective VAT fraction.
D11. A number of streams of expenditure contribute to the tax base, with most VAT deriving from consumers’ expenditure (that is, household consumption). The main expenditure categories that comprehensively cover VAT liabilities are:
- household consumption
- non-profit institutions serving households
- government capital and current expenditure - capital and current expenditure from the VAT traders in the VAT exempt sector
- housing capital expenditure
Input tax adjustments
D12. Net VAT liability is the difference between VAT due on taxable supplies made by registered traders (‘output tax’), and VAT recoverable by traders on supplies made to them (‘input tax’).
D13. VAT liability for the relevant categories can be estimated directly from Office for National Statistics’s National Accounts data, with the one exception of the VAT exempt sector. Businesses making outputs that are exempt from VAT are generally not permitted to reclaim all the VAT on inputs associated with their exempt outputs. To make an adjustment for this irrecoverable input tax, a separate HMRC survey is used to ascertain the proportion of purchases on which VAT cannot be reclaimed.
D14. A further adjustment is made for expenditure by businesses which are legitimately not registered for VAT and, as such, cannot recover their input tax. This adjustment uses a combination of data from the Department for Business and Trade and HMRC information on the distribution of business turnover below the VAT threshold to estimate relevant expenditure. This adjustment is made as part of the ‘Deductions’, detailed in the following section.
D15. Because the calculation of irrecoverable input tax is complex, the level of uncertainty around input tax adjustments is larger than for the other elements.
Deductions
D16. The sum of the VAT liability arising from each of the expenditure categories listed in paragraph D11 gives an estimate of the gross VAT total theoretical liability in each year. However, there are several legitimate reasons why part of this theoretical VAT is not actually collected. These can be grouped into 3 broad categories:
- VAT refunds
- expenditure of traders legitimately not registered for VAT
- other deductions
D17. VAT refunds are made primarily to government departments, NHS Trusts and regional health authorities for specified contracted out services acquired for non-business purposes. A number of other categories of expenditure cannot be separately identified in the overall VAT total theoretical liability calculation, for which VAT can be refunded. The value of these refunds is taken directly from audited HMRC accounts data.
D18. Traders who trade below the VAT threshold can legitimately exclude VAT on their sales. Expenditure on the output of these businesses will have been picked up in the total theoretical liability. To adjust for this, an estimate of relevant expenditure is made using a combination of Department for Business and Trade data and HMRC information on the distribution of business turnover below the VAT threshold.
D19. Other deductions will capture other legitimate schemes and reliefs.
Net VAT receipts
D20. Figures for actual receipts of VAT are taken from HMRC’s published tax receipts figures. The receipts are adjusted to reflect timing effects within each tax year, before being used in the model. A summary of HMRC’s tax receipts can be found on GOV.UK.
D21. For the tax years 2019 to 2020 through to 2022 to 2023 the receipts figure includes an adjustment for the payments which were deferred in 2020 under the VAT Payments Deferral Scheme, and those later further deferred under the VAT Deferral New Payment Scheme. This adjustment ensures that all payments (those already received and those expected to be paid) in respect of liabilities related to these years are properly captured in the VAT gap estimates.
VAT gap
D22. Finally, subtracting the net VAT receipts from the net VAT total theoretical liability gives the VAT gap. The percentage gap is calculated by dividing the VAT gap by the net VAT total theoretical liability. Receipts for the tax year (April to March) are compared with the total theoretical liability for the calendar year, assuming an average 3-month lag between an economic activity and the payment of the corresponding VAT to HMRC. Calculations for VAT total theoretical liability and net VAT total theoretical liability assume a 3-month lag between expenditure and actual VAT receipts. Hence, calendar year expenditure data equates to tax year receipts.
D23. The detailed calculations used to construct the estimated VAT total theoretical liability are continuously reviewed to identify improvements to the methodology. Also, the National Accounts data used to construct the VAT total theoretical liability is subject to updates and revisions by the Office for National Statistics throughout the year as final data becomes available.
D24. In summary, the VAT gap is calculated by subtracting actual VAT receipts from the net VAT total theoretical liability. The net VAT total theoretical liability is calculated by subtracting legitimate deductions from the gross VAT total theoretical liability. Legitimate deductions (as described in D16 to D19) are calculated by adding up refunds, reliefs, theoretical VAT paid to legitimately unregistered traders, and other deductions. The method for calculating Gross VAT total theoretical liability is described in D6 to D10.
Non-payment
D25. Alongside the VAT gap estimate, the VAT gap due to non-payment is also estimated.
D26. Non-payment is an estimate of eventual VAT non-payment attributable to the year of tax debt creation. More information on the non-payment methodology can be found in Chapter L Tax gap by behaviour and customer group.
Chapter E: Alcohol
Spirits and beer (upper bound) estimate
Overview
E1. The estimates of the tax gap for spirits and the beer upper bound are produced using a top-down methodology. The estimate is produced by first estimating the volume of total consumption, and then subtracting legitimate consumption, with the residual being the illicit market, from which we derive the tax gap.

E2. This residual is then turned into an estimate of the proportion of the total market that is supplied through the illicit market by dividing illicit market volume by total consumption volume and then multiplying by 100 to convert it into a percentage. This is termed the illicit market share.

E3. Revenue losses associated with the illicit market are then estimated by combining the illicit market share with data on price, excise duties rates and VAT rates.
E4. Although the spirits and the beer upper bound estimates are calculated using the same underlying methodology there are differences, the three main ones being:
-
the spirits tax gap estimate uses one methodology and is produced with confidence intervals, whilst beer has two methodologies: an upper and a lower bound estimate which are averaged to produce an implied midpoint central estimate
- the spirits and beer estimates use different methods to calculate the uplift factors
- a rolling average is applied to the spirits total consumption estimate to account for the volatility observed
E5. Details of the methodology, including differences, for the estimation of the spirits and beer (upper bound) tax gap are provided in the next sections, followed by the lower bound beer tax gap.
Estimating total consumption
E6. The consumption of spirits or beer bought in the United Kingdom (UK) is estimated using the Living Costs and Food Survey (LCF) from the Office for National Statistics (ONS). LCF estimates are weighted by the ONS to adjust for survey non-response.
E7. Since the LCF only covers purchases within the UK, cross-border and duty-free shopping is added to the consumption of spirits/beer bought in the UK to give total consumption.
Total consumption of UK purchases
E8. The consumption of UK purchased goods in any given year is calculated using the following:
- estimates of household on-licence (consumed at the point of sale, for example, in a pub or restaurant) and off-licence (consumed off the premises, for example from a supermarket) expenditure on spirits/beer from the LCF
- the average number of people in a household estimated from the LCF
- data on average alcohol prices provided by the ONS
- estimates of the UK adult population (ages 18 or over) from the ONS
- uplift factors calculated independently for on-licence and off-licence sectors
E9. Average adult consumption is estimated by dividing average household consumption by the average number of adults in a household. This is then converted into total UK consumption by multiplying by the UK adult population and then applying an uplift factor.

Living Costs and Food Survey
E10. The average weekly expenditure on spirits and beer for UK households is estimated using the LCF. Households participating in the surveys are asked to record their expenditure on alcohol under the relevant specific category of drink (that is wine, spirits, beer, etc.). There is an additional category for recording drinks purchased as part of a ‘round’ of drinks, which will be referred to as ‘other drinks’.
E11. Some of the ‘other drinks’ purchased will be spirits or beer. The calculation for consumption therefore includes a proportion of ‘other drinks’ purchases.
E12. The average weekly expenditure per household is converted to the volume consumed by that household using the average price of spirits/beer. This is then scaled up to an annual figure.
E13. The average consumption of spirits/beer per household is then converted to the average per person, by dividing by the average number of adults in a household. This is scaled up to the UK adult population.
E14. Most under-age drinking is taken into account in the alcohol models. We assume that adults buy most of the alcohol consumed by minors. This under-age alcohol expenditure is therefore included in the adults’ alcohol consumption and is measured by the survey.
E15. Due to the relatively small sample size in the LCF, the average weekly expenditure for spirits or beer is heavily influenced by extreme expenditure values in the data. Outliers in the data have been capped at the 99th percentile.
Cross-border and duty-free shopping
E16. Duty-free is included in the cross-border shopping calculation. Estimates of consumption of goods purchased as cross-border shopping are based on figures produced from the International Passenger Survey (IPS). This provides estimates of the volume of spirits and beer an average adult traveller brings into the country, separately for air and sea passengers. The IPS figures are weighted by the ONS, scaling up the survey data to represent the total cross-border shopping entering the UK.
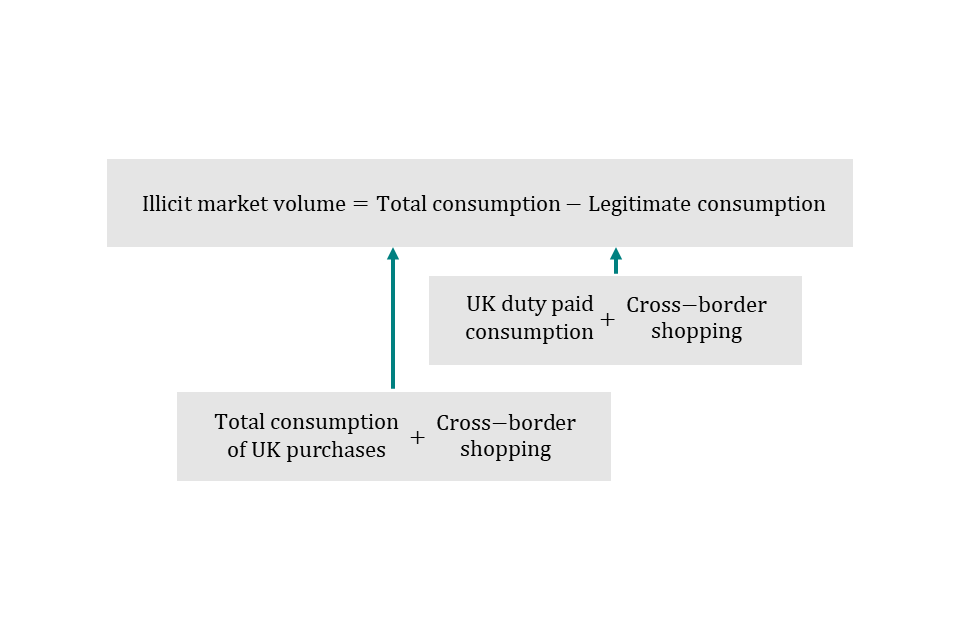
E17. An estimate of the volume of duty-free spirits/beer brought into the country is calculated in the same way, using passengers coming from outside the European Union (EU).
E18. This estimate, however, does not cover sales made on-board ferries, so commercially provided data about deliveries of spirits/beer to ferries are used to supplement the cross-border shopping estimate, and provide a complete figure.
E19. Cross-border shopping is estimated as goods bought overseas, plus goods bought on-board ferries, plus duty-free.

E20. The IPS was suspended during COVID-19 and coverage does not cover all ports. As a result, 2020 to 2021 is projected using a 3-year average of alcohol spending abroad (from 2017, 2018 and 2019 IPS data). This is applied to IPS data on visitor numbers and spending in this period.
From 2021 to 2022 onwards, estimates were adjusted using passenger numbers from the Department for Transport. This account for ports where the IPS had not yet restarted.
Estimates for goods bought on ferries in 2023 to 2024 are based on the average sales from 2022 to 2023. This is due to limited commercial data for earlier years.
Estimating legitimate consumption
E21. Legitimate consumption is calculated as UK duty paid consumption plus cross-border shopping.

E22. Estimates of UK duty paid consumption are taken directly from returns to HMRC of the volumes of spirits/beer on which duty has been paid. Duty is payable once alcoholic goods are released onto the UK market for consumption. Amounts released are referred to as ‘clearances’. For spirits the volumes of ready-to-drink products have been removed from spirits clearances in order to obtain figures for spirits only.
E23. Cross-border shopping is calculated in the same way as for total consumption: goods bought overseas, plus goods bought on-board ferries, plus duty-free.

Estimating the illicit market
E24. Total consumption is the sum of cross-border shopping (as defined in E19) and total consumption of UK purchases (as defined in E9). The illicit market volume is calculated by subtracting legitimate consumption (as defined in E21) from total consumption.
Conversion to monetary losses
E25. Revenue losses associated with the illicit market are then estimated by combining the illicit market share information with price data, duties rates and VAT rate information. The duty portion is calculated as illicit market volume, multiplied by spirits/beer duty rates. This is summed with the VAT portion, which is calculated as illicit volume, multiplied by average price, multiplied by the VAT fraction.
E26. Data on average spirits/beer prices is derived from data provided by the ONS. The prices used in the model are weighted across on-licence and off-licence and for different types of spirits/beer.
E27. The VAT fraction is the portion of the retail price that is VAT — for example, a 20% VAT rate is equivalent to a one-sixth VAT fraction. VAT fractions are calculated annually to capture changes in the VAT rate. This method assumes that VAT is also lost on all purchases. As, in some cases, the final illicit product is sold in legitimate outlets this may not always be the case, and this will be an overestimate of revenue losses.
E28. For the spirits calculation, spirits duty is converted into bulk duty liabilities based on the assumption that spirit’s strength is constant at 38%.
Spirits uplift factor
E29. The LCF data for alcohol are subject to under-reporting, they may under-represent certain sub-populations with a high average alcohol consumption, and do not cover the full extent of the alcohol market so an uplift factor is necessary to correct for these biases. This uplift factor is calculated by taking estimates of consumption from the LCF in the base year and comparing these with independent estimates of total consumption.
E30. To do this we take a year in which there is believed to be little or no illicit market and use HMRC clearance data as a true indication of total consumption. In order to reduce sampling error, the uplift factor is derived by taking the average of 3 years of data from the base years: 1990 to 1991, 1991 to 1992 and 1992 to 1993.
E31. Separate uplift factors are calculated for on-licence and off-licence markets, and the formula is defined as legitimate consumption in the base years, divided by estimated total consumption in the base years.

E32. The uplift factors for on-licence and off-licence are 3.5 and 2.0 respectively.
Beer Uplift factor
E33. The basis for this uplift factor is the same as for spirits, an average of the 3 base years is used where there is assumed to be no illicit market. However, due to the variation in price between draught and packaged beer, a different uplift factor to spirits is required.
E34. To calculate uplift factors for draught and packaged beer, LCF data is split between on-licence and off-licence markets and then into draught and packaged beer. This uses market shares estimated from the ONS and British Beer and Pub Association (BBPA) data.
E35. The base year uplift factors are defined as legitimate consumption in the base years, divided by estimated total consumption in the base years.

E36. An additional uplift for packaged beer is calculated, which varies year-on-year. This assumes that there is no or a negligible illicit market in draught beer, whereby consumption is equal to clearances in every year. The draught beer uplift and base year uplifts are combined to compute the packaged beer uplift. This is achieved by multiplying the draught uplift in the year of estimation by the ratio of packaged to draught uplifts in the base years.

E37. Since 2020 to 2021, the packaged beer uplift factor has been projected based on an average of the previous 3 years, resulting in an uplift between 2.8 and 3.0. This is due to model sensitivities around the methodology for calculating the uplift factor.
Removing spirit-based ready-to-drinks
E38. Spirit-based ready-to-drinks (RTDs) are packaged beverages that are sold in a prepared form, ready for consumption, such as alcopops.
E39. The LCF expenditure data for spirits includes expenditure on RTDs.
E40. RTDs are currently included in the ‘other excise duties’ estimates, so are removed from the spirits tax gap to avoid double counting. To remove RTDs, we estimate the proportion of total expenditure attributable to ready-to-drinks using data on expenditure from the ONS, and total pure alcohol clearances on spirits and RTDs from HMRC clearances.
Upper and lower confidence intervals in the spirits estimate
E41. The variation in the LCF is used to construct 95% confidence intervals around the central estimate. They indicate the potential size of chance fluctuations in the estimate due to sampling error. They do not take into account systematic error from the model assumptions in the central estimate.
Smoothing spirits total consumption
E42. The number of LCF responses reporting spirits expenditure is small relative to the survey’s sample size and so estimated average household expenditure can vary substantially between years. A 3-year rolling average is applied to the final total consumption estimate for spirits to reduce this volatility and make the tax gap trend clearer.
E43. The spirits tax gap estimate since the tax years 2020 to 2021 has been projected based on the illicit market share for 2019 to 2020. This is due to data from recent years producing unreliable estimates.
Beer lower estimate
Overview
E44. The beer tax gap lower estimate is produced using a bottom-up methodology. This means estimates of the illicit market are made directly, by estimating the fraud components that make up the illicit market. The following types of illicit beer are included in the lower estimate:
- diversion of UK-produced beer
- drawback fraud
E45. Some of this illicit beer is recovered through HMRC compliance activity, so this is subtracted to give the net tax gap. The tax gap estimate is defined as diversion of UK produced beer, plus drawback fraud, minus seizures of illicit beer.

E46. A number of beer fraud channels are not included in this methodology as we are currently unable to estimate them. This is one of the reasons it is a lower bounding estimate. These include:
- smuggled beer
- diversion of foreign produced beer
- counterfeit beer
- any other fraud we do not know about
Diversion of UK-produced beer
E47. Diversion fraud occurs when beer is moved in duty suspense to the EU and is subsequently diverted back into the UK under the cover of false documentation. The taxes are not declared on the beer and the illicit product enters the UK market.
E48. We estimate that diversion fraud is equal to the amount of beer moved in duty suspense from the UK to certain EU member states, minus legitimate demand for UK branded beer in those countries. That is, we assume that any UK beer which is not feeding demand abroad will be diverted back to the UK illicit market.

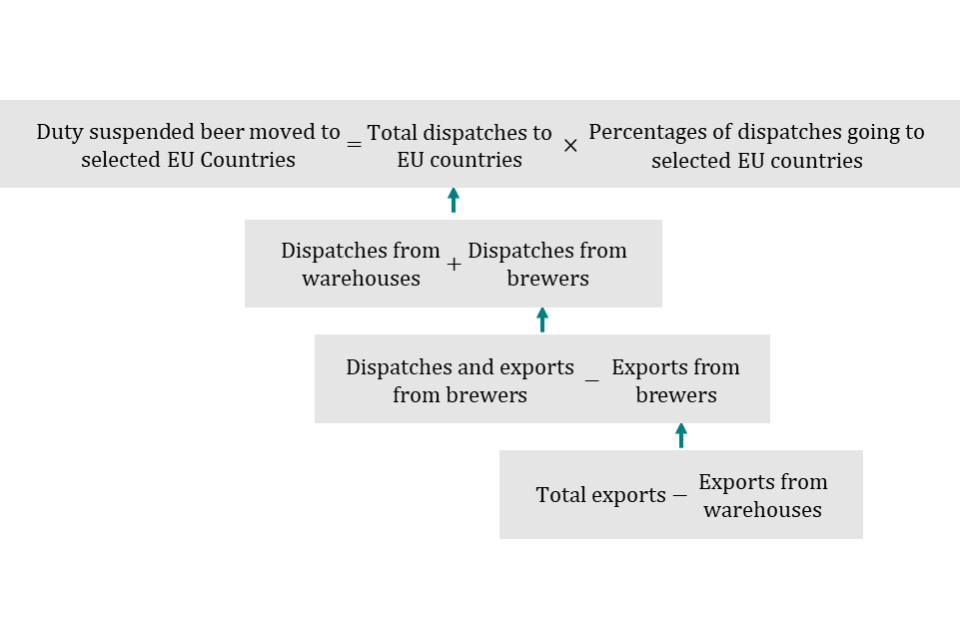
E49. The total amount of beer moved in duty suspense from the UK to the EU includes dispatches from both excise warehouses and brewers. Dispatches from excise warehouses are taken directly from Excise Warehouse Returns (W1 form). Dispatches from brewers are estimated using data from Beer Duty Returns (EX46 form). Total beer dispatches are calculated by summing warehouse and brewer dispatches.

E50. Brewers return data is used for dispatches (movements to EU countries) and exports (movements to non-EU countries) and it cannot be disaggregated. So, to estimate dispatches from brewers, we subtract an estimate of exports from brewers.

E51. Exports from brewers are estimated as total exports, from Customs Handling of Import and Export Freight (CHIEF), minus exports from Excise Warehouse Returns (W1 form).

E52. To preserve the lower bounding nature of this estimate, we only include dispatches to certain EU countries. These countries have been selected based on a number of factors, including: proximity to the UK; the differential in price; operational indications of risk and patterns of supply.
E53. The estimate of beer dispatches, described in paragraphs E48 and E50, cannot be broken down to recipient country. Therefore, we use an alternative data source, UK trade data, which does include a breakdown by country. The proportion of beer dispatched to the selected EU countries is taken from UK trade data and applied to the estimated total dispatches to produce an estimate for dispatches to these selected EU countries.
E54. UK trade data is not used to directly estimate dispatches to these countries as it does not include certain types of movements. More detail is provided on this in paragraph E68.
E55. To summarise, total duty suspended beer moved to selected EU countries is calculated as the product of the percentage of dispatches going to selected EU countries (as defined in E53) and total dispatches to EU countries. Total dispatches to EU countries are defined as the sum of dispatches from warehouses and brewers. Dispatches from brewers must be calculated by subtracting the difference between total exports and warehouse exports from total dispatches and exports from brewers.
Drawback fraud
E56. Drawback fraud occurs when goods are moved to the EU and the duty is reclaimed via drawback (a refund of UK beer or spirits duty). Duty is then paid at the lower rate in the destination country and the goods are illicitly returned to the UK.
E57. To estimate drawback fraud, we estimate the volume of beer corresponding to certain drawback claims, then subtract the legitimate demand for beer in the selected destination countries.

E58. To preserve the lower bounding nature of this estimate, we only include drawback if it is claimed for dispatch by a business not part of HMRC Large Business. The value of these drawback claims is converted to volume of beer by dividing by the average duty rate for beer.
E59. The volume is then adjusted using the proportion of dispatches going to the selected EU countries. This gives an estimate of the amount of beer going to the selected countries with drawback claimed by small and medium sized enterprises.

Legitimate demand in selected EU countries
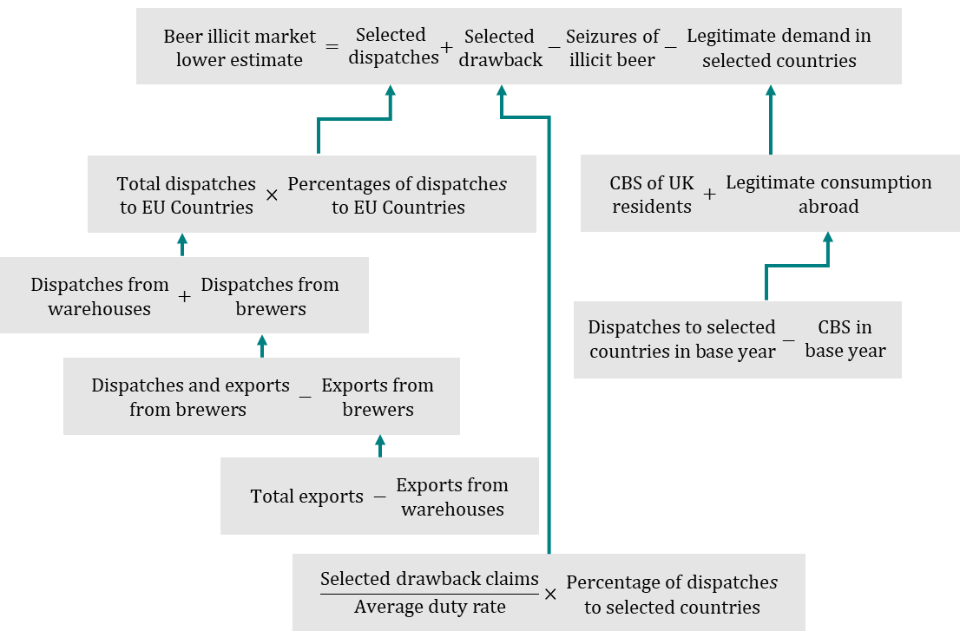
E60. Some of the beer moved to the selected EU countries will be supplying legitimate demand within those countries, rather than being diverted to the UK illicit market. We make one overall estimate of legitimate demand in the selected EU countries and subtract it from the sum of selected beer dispatches and selected beer for drawback.
E61. We have purposely overestimated legitimate demand by only accounting for the riskiest countries, which produces an underestimate of the illicit market, in order to maintain the lower bounding nature of the tax gap estimate.
E62. The estimate of legitimate demand in other countries sums cross-border shopping bought by UK residents and legitimate consumption abroad. The latter may include:
- consumption by UK expatriates
- consumption by UK residents while abroad
- consumption by foreign nationals
- beer in transit to other countries

E63. Cross-border shopping is estimated using data from the IPS. More detail is provided in paragraph E16. Only passengers from the selected EU countries are included.
Legitimate consumption of UK produced beer abroad
E64. We could not find reliable data on legitimate consumption of UK produced beer abroad. So, we estimate it based on the assumption that in a certain year, when the illicit market upper estimate was low, there was negligible illicit activity meaning all dispatches to the selected EU countries were consumed legitimately. This is likely to provide an overestimate of legitimate consumption abroad, as there would likely be some level of fraud in these years. This supports the methodology being a lower estimate of the tax gap.
E65. For stability, an average of 2 years is used: 2000 to 2001 and 2001 to 2002. We refer to these 2 years as the ‘base year’.
E66. Brewers return data is not available for years prior to 2007. Consequently, we use an alternative data source, UK trade data, to estimate dispatches in the base year.
E67. In the base year we assume that all dispatches supply either cross-border shopping by UK residents or legitimate consumption abroad. We subtract an estimate of cross-border shopping in the base year from dispatches in the base year; the remainder is assumed to be legitimate consumption abroad.

E68. We believe that UK trade data may underestimate beer dispatches in the base year as it does not record certain types of beer movement. These include:
- goods in transit
- deliveries to embassies
- deliveries to Navy, Army, and Air Force Institutes (NAAFI)
E69. Additionally, as the threshold for recording goods on UK trade data is relatively high, beer may have a higher proportion of small traders than other commodities. This may mean the standard adjustment applied to UK trade data to account for small traders may be too low for beer.
E70. To account for these concerns, we uplift the UK trade data. There is very little evidence to indicate the actual scale of uplift required. Comparison with our calculated dispatches in later years led us to apply a factor of 2. Again, the high level of this adjustment may result in this being an overestimate of legitimate demand. This is in keeping with the lower bounding methodology for the tax gap, as higher legitimate demand would see a lower estimate for the illicit market.
Illicit market lower estimate
E71. To summarise, the beer illicit market lower estimate is calculated by summing selected dispatches (as defined in E55) and selected drawback (as defined in E58 and E59), before subtracting seizures of illicit beer and legitimate demand in selected countries. Legitimate demand in selected countries is defined as cross-border shopping (CBS) of UK residents plus legitimate consumption abroad (as defined in E67).
E72. Since the tax year 2016 to 2017, the beer illicit market lower estimate has been projected to better reflect changes in fraud. This is calculated by keeping the gross tax gap constant, whilst using operational intelligence as a proxy to capture the impact of changes in the illicit market.
Implied mid-point estimate
E73. The implied mid-point estimate is calculated as the average of the upper and lower estimates. It is only intended as an indicator of long-term trend — the true tax gap could lie anywhere within the bounds.
E74. The bounds do not take account of any systematic tendency to over- or under-estimate the size of the tax gap that might arise from the modelling assumptions.
Wine central estimate
E75. We have not estimated the illicit market share for wine due to the unavailability of a key commercial data source previously used to estimate the wine tax gap. We therefore include wine within our tax gap estimate for ‘Other excise duties’, which is based on an illustrative method. See ‘Chapter J: Other taxes’.
Chapter F: Tobacco
Overview
F1. The estimate of the tax gap for tobacco is produced using a top-down methodology. We estimate the volume of total consumption, and then subtract legitimate consumption. The residual is the estimated illicit market, from which we derive the tax gap.

F2. The proportion of the total market that is supplied through the illicit market is determined by dividing illicit market volume by total consumption volume. This is termed the illicit market share.

F3. Revenue losses associated with the illicit market are then estimated by combining the illicit market share with the related market prices, excise duty rate and VAT rate.
Methodology
F4. The estimates of the illicit market for cigarettes and hand-rolling tobacco are produced using a top-down methodology, as described in paragraphs F1 to F3. Adding both elements together gives an estimate for the overall tobacco tax gap.
F5. The methodology used for all tax years excluding 2020 to 2021 to 2022 to 2024 is based on the descriptions set out in the ‘total consumption’ section below. The calculations of legitimate consumption apply to all years.
F6. For the three tax years from 2020 to 2021 up to 2022 to 2023 the Office for National Statistics temporarily removed tobacco consumption questions from their Opinions and Lifestyle Survey used to calculate total consumption. These questions have been introduced again from tax year 2023 to 2024. We have projected these missing years using linear interpolation of the illicit market share in the tax years 2019 to 2020 and 2023 to 2024.F7. To account for a change in the survey design, we adjust consumption data for tax years 2018 to 2019 and 2019 to 2020. This model adjusts data from the tax year 2018 to 2019 to tax year 2019 to 2020 based on time series discontinuity analysis produced by the Office of National Statistics and an uplift factor based on AB testing of question design. We apply this uplift to average daily consumption survey data.
Total consumption
F8. The total consumption in any given year is calculated using the following:
-
estimates of prevalence (proportion of the population that smoke from the General Lifestyle Survey, the Opinions and Lifestyle Survey and Health Survey for England)
- estimates of consumption per smoker from the General Lifestyle Survey, the Opinions and Lifestyle Survey and Health Survey for England
- estimates of the adult population (ages 16 or over) from the Office for National Statistics
- an uplift factor to account for under-reporting of self-declared tobacco consumption
F9. The estimate of total UK cigarettes and hand-rolling tobacco consumption for each year is a product of the estimates of cigarette and hand-rolling tobacco smoking prevalence and consumption per smoker for declared and undeclared smokers.
F10. . We uplift estimated consumption figures to account for survey non-declaration using medical evidence collected during Health Survey for England.
Uplift factor
F11. Separately to account for under-declaration of tobacco consumption, we apply an uplift factor calculated by taking estimates of total consumption from the General Lifestyle Survey in a base year. In cigarettes the base year is 1996 to 1997, and in hand-rolling tobacco it is an average of 3 years, 1983 to 1986. Estimates of total consumption in base years are compared with consumption of actual clearances to HMRC and an estimate of legitimately purchased cigarettes from abroad.

F12. The uplift factors for the cigarettes and hand-rolling tobacco estimates are 1.5 and 1.1 respectively.
Upper and lower bounds for total consumption
F13. The uncertainties in the survey data used to create these estimates mean that it is not possible, with sufficient accuracy, to produce a single point estimate of total consumption. However, due to the methodology we use, it is difficult to produce confidence intervals. Instead, we use the survey data to produce an upper bound and lower bound for total consumption. This allows us to produce a range for total consumption that takes account of the uncertainty in the underlying data.
F14. The one difference between the upper and lower bound calculations is the treatment of dual smokers. Dual smokers are individuals who consume both cigarettes and hand-rolling tobacco. In the upper bound calculation, the majority of the dual smokers are considered to be cigarette smokers. In the lower bound estimate, we assume that the majority smoke hand-rolling tobacco. This is explained further in the following tables and sections.
Table F.1 Cigarettes upper and hand-rolling tobacco lower bound assumptions
| Allocation of total tobacco consumption for estimates | Allocation of total tobacco consumption for estimates | |
|---|---|---|
| Opinions and Lifestyle Survey Options | Cigarette upper bound assumption | Hand-rolling tobacco lower bound assumption |
| Cigarettes only | 100% | 0% |
| Dual smokers: cigarettes and hand-rolling tobacco, but mainly cigarettes | 99% | 1% |
| Dual smokers: cigarettes and hand-rolling tobacco, but mainly hand-rolling tobacco | 49% | 51% |
| Hand-rolling tobacco only | 0% | 100% |
Table F.2 Cigarettes lower and hand-rolling tobacco upper bound assumptions
| Allocation of total tobacco consumption for estimates | Allocation of total tobacco consumption for estimates | |
|---|---|---|
| Opinions and Lifestyle Survey Options | Cigarette lower bound assumption | hand-rolling tobacco upper bound assumption |
| Cigarettes only | 100% | 0% |
| Dual smokers: cigarettes and hand-rolling tobacco, but mainly cigarettes | 51% | 49% |
| Dual smokers: cigarettes and hand-rolling tobacco, but mainly hand-rolling tobacco | 1% | 99% |
| Hand-rolling tobacco only | 0% | 100% |
F15. The upper bound of total cigarette or hand-rolling tobacco consumption is calculated firstly by estimating consumption levels from smokers who only smoked cigarettes or hand-rolling tobacco. This is added together with a maximum consumption of cigarettes or hand-rolling tobacco that could be smoked by dual smokers.
F16. The lower bound of total cigarette or hand-rolling tobacco consumption is calculated firstly by estimating consumption levels from smokers who only smoked cigarettes or hand-rolling tobacco. This is added together with a minimum consumption of cigarettes or hand-rolling tobacco that could be smoked by dual smokers.
F17. Tobacco tax gap estimates up to and including quarter 3 of 2011 to 2012 use the General Lifestyle Survey as the base estimate for tobacco consumption. These estimates are supplemented with Opinions and Lifestyle Survey data on dual smokers where this is added/subtracted to obtain the upper and lower bounds. All years from quarter 4 of 2011 to 2012 are based on Opinions and Lifestyle Survey data only.
Legitimate consumption
F18. Estimates of legitimate consumption include:
- UK duty paid consumption
- Cross-border and duty-free shopping
UK duty paid consumption
F19. Estimates of UK duty paid consumption are taken directly from tax returns to HMRC (clearance data) on the volumes of cigarettes and hand-rolling tobacco on which duty has been paid, along with the actual amounts of money.
Cross-border and duty-free shopping
F20. Estimates of consumption of goods purchased as cross-border shopping are based on data from the International Passenger Survey (IPS). This provides estimates of the number of cigarettes and/or hand-rolling tobacco that an average adult traveller brings into the country, separately for air and sea passengers. The IPS figures are weighted by the Office of National Statistics, scaling up the survey data to represent the total cross-border shopping entering the UK.
F21. This estimate, however, does not cover sales made on-board ferries. Commercially provided data about deliveries of cigarettes to ferries is used to supplement the cross-border shopping estimate.
F22. Duty-free cigarettes/hand-rolling tobacco brought into the UK are also estimated from the IPS, using passengers coming back from outside the EU.
F23. Legitimate consumption is estimated as UK duty paid consumption, plus cross-border shopping, plus duty-free.

F24. The IPS was suspended during COVID-19 and coverage does not cover all ports. As a result, 2020 to 2021 is projected using a 3-year average of tobacco spending abroad (from 2017, 2018 and 2019 IPS data). This is applied to IPS data on visitor numbers and spending in this period. From 2021 to 2022 onwards, estimates were adjusted using passenger numbers from the Department for Transport. This account for ports where the IPS had not yet restarted. Estimates for goods bought on ferries in 2023 to 2024 are based on the average sales from 2022 to 2023. This is due to limited commercial data for earlier years.
Conversion to monetary losses
F25. All calculations to this point have been made on volumes of cigarettes or hand-rolling tobacco. Revenue losses associated with the illicit market are then estimated by combining the illicit market share information with price data, duty, and VAT rate information. Volumes are converted to estimates of revenue losses by multiplying by the sum of specific duty and ad valorem liabilities. Ad valorem liabilities are calculated as average price multiplied by the sum of ad valorem duty and the VAT fraction.

F26. The average price is taken as the weighted average price of all cigarettes or hand-rolling tobacco that were UK duty paid. The weighted average price is calculated by weighting the retail price of each product by the share of clearances in the cigarette or hand-rolling tobacco market.
F27. The VAT fraction is the proportion of the retail price that is VAT — for example, a 20% VAT rate is equivalent to a one-sixth VAT fraction. VAT fractions are calculated annually to capture changes in the VAT rate. This method assumes that VAT is also lost on all purchases. In some cases, the final illicit product is sold in legitimate outlets where VAT is paid, so this method results in an overestimate of revenue losses.
Summary of cigarette methodology
F28. In summary, the illicit market for cigarettes is calculated as the sum of declared and undeclared consumption, minus legitimate consumption.
F29. Declared consumption is defined as the total adult population multiplied by the uplift factor, multiplied by the sum of declared consumption by cigarettes and dual smokers. The upper bound assumes most dual smokers smoke cigarettes, whilst the lower bound assumes most smoke hand-rolling tobacco. Undeclared consumption is defined as the product of the non-smoker population, the uplift factor, the under-declared smokers’ prevalence, and the consumption per under-declared smoker.
F30. Legitimate consumption is defined as UK duty paid consumption (from HMRC clearance data), plus cross-border shopping (the sum of on-board ferry sales and the average amount per traveller, multiplied by the number of travellers), plus duty-free (from the International Passenger Survey).
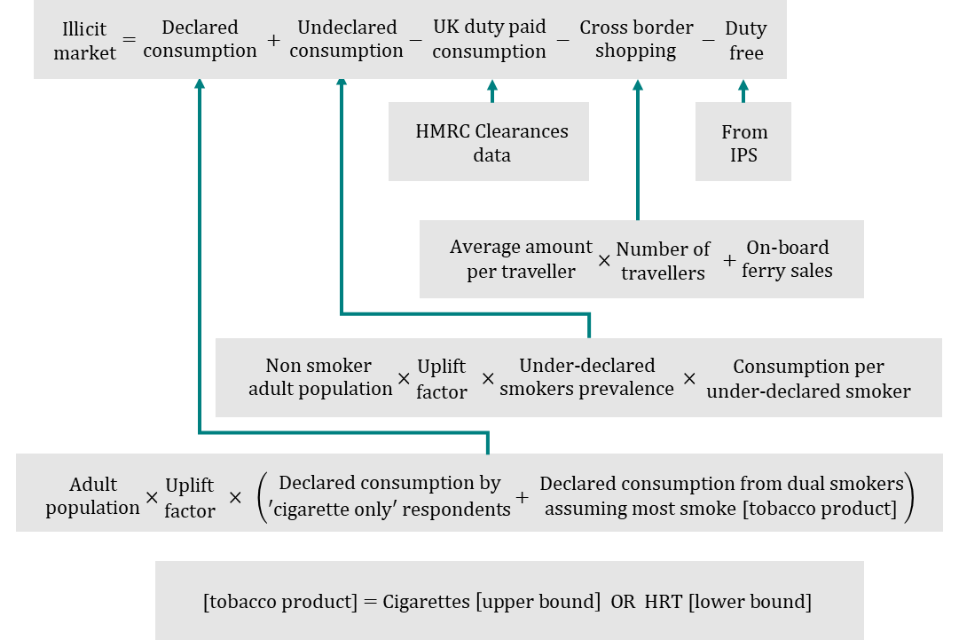
Summary of hand-rolling tobacco methodology
F31. In summary, the illicit market for hand-rolling tobacco is calculated as the sum of declared and undeclared consumption, minus legitimate consumption.
F32. Declared consumption is defined as the total adult population multiplied by the uplift factor, multiplied by the sum of declared consumption by hand-rolling tobacco and dual smokers. The upper bound assumes most dual smokers smoke hand-rolling tobacco, whilst the lower bound assumes most smoke cigarettes. Undeclared consumption is defined as the product of the non-smoker population, the uplift factor, the under-declared smokers’ prevalence, and the consumption per under-declared smoker.
F33. Legitimate consumption is defined as UK duty paid consumption (from HMRC clearance data), plus cross-border shopping (the sum of on-board ferry sales and the average amount per traveller, multiplied by the number of travellers), plus duty-free (from the International Passenger Survey).
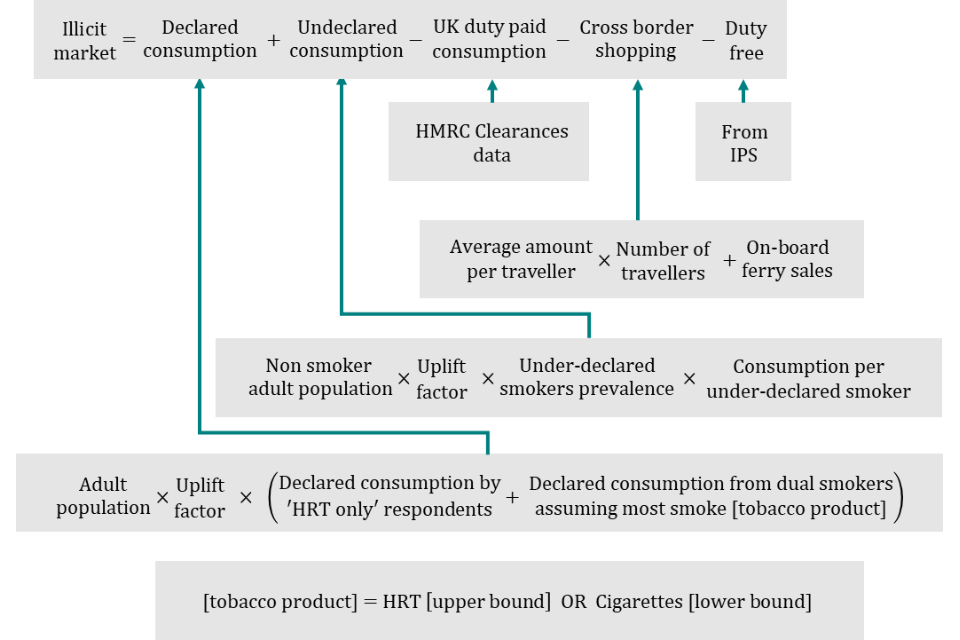
Chapter G: Hydrocarbon oils (fuel duty)
G1. The hydrocarbon oils duty gap is estimated using a combination of established top-down and bottom-up methodologies based on fuel consumption data and a random enquiry programme for the use of illicit diesel. The methodologies outlined in this chapter will refer to the diesel tax gap.
G2. The misuse of other fuels (for example, petrol) has been excluded on the basis that this is believed to be negligible, the scale of which is not currently quantifiable. Other fuel duties do however form a part of hydrocarbon oils duty total theoretical liabilities.
Methodology
G3. A bottom-up methodology is used to estimate the diesel tax gap from the tax year 2016 to 2017 onwards based on random enquiry programme data. The Great Britain (GB) and Northern Ireland (NI) diesel tax gaps are calculated separately but the methodologies are identical.
G4. Figures prior to 2016 to 2017 are calculated using a top-down methodology based on fuel consumption data. This methodology was no longer fit for purpose from the tax year 2013 to 2014 as it was not sensitive enough to accurately measure the low tax gap. This meant the estimates for 2013 to 2014 were rolled forward for 2014 to 2015 and 2015 to 2016 before a bottom-up approach was introduced in 2016 to 2017.
G5. Since previous years are based on a top-down methodology, figures from 2016 to 2017 onwards are not directly comparable to these.
G6. The methodology below describes the bottom-up approach used from 2016 to 2017.
G7. Summary of methodology:
- legitimate consumption is based on the returns that HMRC receives from the volumes of diesel on which duties have been paid (HMRC clearances)
- illicit consumption is estimated using the proportion of vehicles found to be misusing rebated fuel (fuel taxed at a reduced rate) in random sample surveys conducted by HMRC in 2017, 2020 and 2023
- revenue losses (gross tax gap) associated with illicit consumption are estimated using average retail prices, duty rates and VAT rates
- the net tax gap is then calculated as the gross tax gap minus compliance yield.
Estimating total consumption
G8. Total consumption is calculated as legitimate consumption plus illicit consumption.

G9. HMRC conducted random surveys in April to June 2017, January to March 2020 and September to November 2023, where vehicles were stopped at the roadside and tested for illicit diesel. In all surveys, a stratified sample of 1,900 vehicles across the UK (1,500 in GB and 400 in NI) was used. The sample was stratified by vehicle type and region to ensure the results were representative of all vehicles across the UK.
G10. The proportion of vehicles found to be misusing rebated fuel in each survey is referred to as the strike rate. This is calculated by taking the number of vehicles found to be misusing rebated fuel divided by the number of vehicles tested. The strike rate is used as an estimate of the proportion of vehicles misusing rebated fuel in the UK.

G11. The strike rate is then used alongside legitimate consumption to give estimates for total and illicit consumption. A separate strike rate is calculated in each survey for GB and NI. The strike rate created using 2017 survey data is used for tax years 2016 to 2017, 2017 to 2018 and 2018 to 2019, with the 2020 survey strike rate used for tax years 2019 to 2020, 2020 to 2021 and 2021 to 2022, and the 2023 survey strike rate used the tax year 2022 to 2023 and 2023 to 2024.
G12. To calculate total diesel consumption, we add legitimate consumption and illicit consumption. Legitimate consumption is made up of HMRC clearances. Illicit consumption is defined as the product of HMRC clearances, and the strike rate (defined in G10) divided by one minus the strike rate.
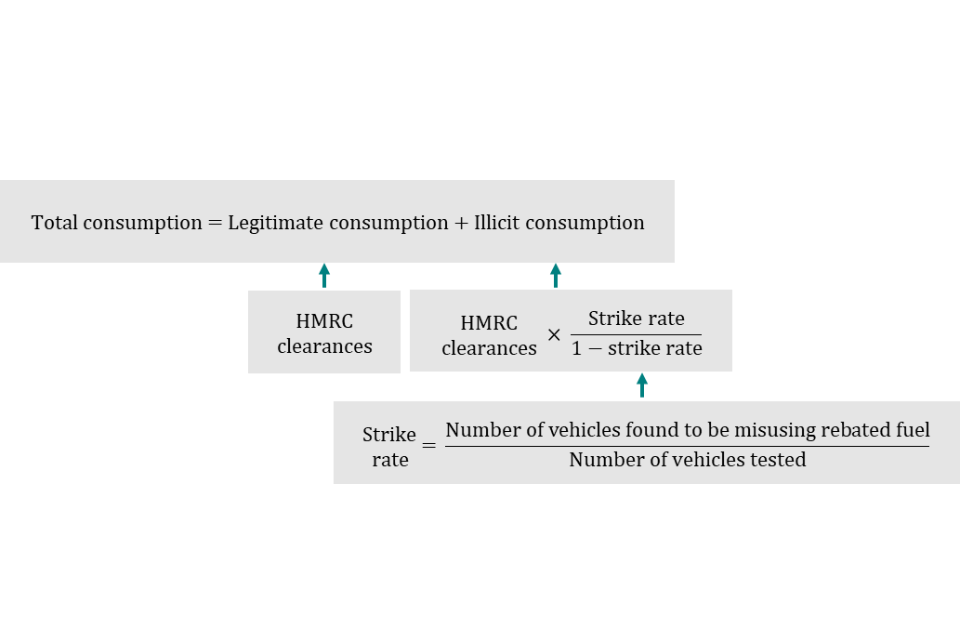
Conversion to monetary losses
G13. The diesel tax gap is driven by the misuse of rebated fuel. Rebated fuel is subject to a lower duty rate and has a lower retail price including VAT. Revenue loss occurs where this fuel is misused, and so should have been subject to a higher rate of fuel duty and additional VAT.
G14. In order to estimate the revenue losses associated with the misuse of rebated fuel, the duty and VAT paid needs to be taken into account. Therefore, the difference between rebated and un-rebated duty rates has been used to estimate the duty loss associated with the illicit market.
G15. Similarly, the difference in average retail prices for rebated fuel and un-rebated diesel has been used to estimate the VAT loss associated with the illicit market. Published data from the Department for Energy Security and Net Zero has been used to calculate average retail prices.
G16. These calculations provide the revenue losses associated with illicit consumption, which we describe as the gross tax gap.
G17. The net tax gap is then calculated as the gross tax gap minus compliance yield.
Confidence intervals
G18. The upper and lower estimates correspond to confidence intervals that indicate the range where the true value of the illicit market may lie and arises due to random sampling error in calculating the strike rate.
Exclusions
G19. Current estimates relate to the misuse of marked rebated gas oil (red diesel) in road vehicles only and do not include fuel laundering or smuggling of oil. The misuse of rebated oil in sectors affected by the April 2022 rebated fuel reform is assumed to have the same strike rate as that seen on roads. This misuse is also included in the estimate. Due to small price differences between the Republic of Ireland and Northern Ireland, cross-border shopping is excluded.
Chapter H: Estimates using random enquiry programmes
H1. This chapter covers components of the Income Tax, NICs, and Capital Gains Tax and the Corporation Tax gaps which are estimated using random enquiry programme (REP) data. Illustrative estimates indirectly estimated using the REP results for Self Assessment large partnerships and the large businesses PAYE gap are also explained in this chapter.
H2. The estimates from the Self Assessment REP are combined with the Self Assessment large partnerships (5 or more partners) estimate to produce an estimate for the overall Self Assessment tax gap. Other components of PAYE and Corporation Tax gaps are estimated using risk-based methodologies which are explained in ‘Chapter I’. Estimates for the hidden economy and marketed avoidance schemes sold primarily to individuals are combined with the overall Self Assessment and PAYE tax gaps to produce the Income Tax, NICs, and Capital Gains Tax gap estimate. Our methodology for these is explained in ‘Chapter K’.
REP estimates
H3. There are 3 REPs which are used to produce tax gap estimates. They cover:
- Self Assessment individuals and small partnerships (covering Self Assessment business and Self Assessment non-business taxpayers)
- PAYE small businesses
- Corporation Tax for small businesses
H4. REPs involve undertaking compliance checks for a randomly selected sample of customers and scaling up the findings from the sampled cases to the relevant full population. Each return selected is subject to a full compliance check involving a complete examination of records.
Populations and sampling
H5. The sizes of the samples for the 3 programmes are shown in Tables H.1, H.2 and H.3 below.
Table H.1: Sample sizes for the Self Assessment REP
| Self Assessment — Tax return year | Self Assessment — Sample size |
|---|---|
| 2005 to 2006 | 5,234 |
| 2006 to 2007 | 2,925 |
| 2007 to 2008 | 2,864 |
| 2008 to 2009 | 2,708 |
| 2009 to 2010 | 2,116 |
| 2010 to 2011 | 2,029 |
| 2011 to 2012 | 2,238 |
| 2012 to 2013 | 2,190 |
| 2013 to 2014 | 2,042 |
| 2014 to 2015 | 1,770 |
| 2015 to 2016 | 2,118 |
| 2016 to 2017 | 2,258 |
| 2017 to 2018 | 1,809 |
| 2018 to 2019 | 2,531 |
| 2019 to 2020 | 1,898 |
| 2020 to 2021 | 2,041 |
| 2021 to 2022 | 1,868 |
Note for Table H.1:
- Sample size figures from 2010 to 2011 onwards have been adjusted due to reclassifying some cases as being within the population of interest.
Table H.2: Sample sizes for PAYE REP
| PAYE — Tax return year | PAYE — Sample size | |
|---|---|---|
| 2005 to 2006 | 1,285 | |
| 2006 to 2007 | 1,184 | |
| 2007 to 2008 | 1,077 | |
| 2008 to 2009 | 1,174 | |
| 2009 to 2010 | 1,180 | |
| 2010 to 2011 | 496 | |
| 2011 to 2012 | 673 | |
| 2012 to 2013 | 692 | |
| 2013 to 2014 | 758 | |
| 2014 to 2015 | 780 | |
| 2015 to 2016 | 714 | |
| 2016 to 2017 | 660 | |
| 2017 to 2018 | 678 | |
| 2018 to 2019 | 681 | |
| 2019 to 2020 | 623 | |
| 2020 to 2021 | 676 | |
| 2021 to 2022 | 510 | |
| 2022 to 2023 | 672 | |
| 2023 to 2024 | 658 |
Note for Table H.2:
- Since the tax year 2015 to 2016 the PAYE sample size given is for small businesses only. Before 2015 to 2016 HMRC’s former small and medium-sized enterprises (SME) customer group classification was used.
Table H.3: Sample sizes for Corporation Tax REP
| Corporation Tax — Accounting period ending in year | Corporation Tax — Sample size |
|---|---|
| 2005 to 2006 | 419 |
| 2006 to 2007 | 460 |
| 2007 to 2008 | 492 |
| 2008 to 2009 | 491 |
| 2009 to 2010 | 480 |
| 2010 to 2011 | 490 |
| 2011 to 2012 | 448 |
| 2012 to 2013 | 576 |
| 2013 to 2014 | 419 |
| 2014 to 2015 | 458 |
| 2015 to 2016 | 266 |
| 2016 to 2017 | 451 |
| 2017 to 2018 | 332 |
| 2018 to 2019 | 354 |
| 2019 to 2020 | 324 |
| 2020 to 2021 | 327 |
| 2021 to 2022 | 358 |
Note for Table H.3:
- Since the tax year 2016 to 2017 the Corporation Tax sample size given is for small businesses only. Before 2016 to 2017 HMRC’s former small and medium-sized enterprises (SME) customer group classification was used. Sample size figures from 2011 to 2012 onwards have been revised following a filtering alignment which has elicited updates to case classifications in the sample.
H6. To produce estimates for the total gross tax gap for each target population from the samples in Tables H.1, H.2 and H.3, the average amount of under-declared tax liability identified from the random enquiries is multiplied by the number of relevant taxpayers in the population.
H7. Adjustments are made to the population for cases deselected because they are outside of the population of interest, for example, the business is no longer operating or is part of the mid-sized or large businesses customer group.
Self Assessment
H8. The Self Assessment REP allows us to estimate the Income Tax, NICs, and Capital Gains Tax gap arising from under-declaration of tax liabilities of individuals in Self Assessment and is used alongside operational compliance data. Results from compliance checks are scaled up to the total number of individuals who are sent a Self Assessment notice to file and who are in the population of interest. For individuals not covered by the REP, operational compliance check data is used. Further details regarding this data are given in the ‘Compliance check data’ section of this chapter.
H9. In this context, ‘individuals’ means individuals who are self-employed, pensioners, and small partnerships (with up to 4 partners), as well as those who are employees or may only have investment income. Self-employed and small partnerships form the business component of the Self Assessment REP, the remaining individuals form the non-business component. Large partnerships (with 5 or more partners) are excluded from the REP and are estimated for separately.
H10. The random sample used for the programme is selected from Self Assessment taxpayers issued with a notice to file a return. The sample is drawn by a systematic process that selects every “nth” notice. The sampling interval, n, is determined by dividing the total number of returns issued by the required sample size (rounded down to the nearest whole number).
H11. When a non-business taxpayer’s return includes a partnership income schedule, and no other income, reliefs or charges, we deselect that return. This is because the returns of individuals who are partners will automatically be included in any compliance check resulting from the selection of a partnership return.
H12. The 2009 to 2010 tax year is the last year which uses a simple random sample, as random samples for subsequent years have been stratified to improve the accuracy of the results. Samples drawn from Self Assessment business taxpayers are stratified by turnover from 2010 to 2011 onwards, with samples drawn from Self Assessment non-business taxpayers stratified by level of income from 2011 to 2012 onwards. Our stratification was updated from 2017 to 2018 onwards to also consider if a taxpayer has been identified as wealthy (individuals with income greater than £200,000 per annum or assets over £2 million).
H13. From 2015 to 2016 we used an optimal allocation method to increase the accuracy of our estimates. When sampling, we consider the variability of the tax at risk across the strata in the population. We select a greater proportion of cases in strata where the variance of tax at risk values is known to be high.
H14. Self Assessment business consists of the self-employed and partnerships. Self Assessment non-business consists of employees, pensioners, trusts and all other types of Self Assessment taxpayers. To improve how representative the sample is, weighting is applied based on how these customer groups are distributed across the population for the relevant tax year.
H15. Due to a relatively small sample size and large natural variance in the levels of under-declared liabilities from year to year, a smoothing approach has been used for small partnerships from 2010 to 2011 (when the stratification of business taxpayers was introduced). A 3-year moving average with a double weighting given to the current year is used to smooth the data. This ensures that the resulting estimates are less susceptible to sampling variability and more indicative of longer-term trends.
PAYE
H16. The PAYE REP allows us to estimate the tax gap arising from PAYE failures and other irregularities of small businesses. Results from the PAYE REP are scaled up to the total number of small business PAYE schemes.
H17. The employer may be an individual, partnership, public body, charity, or a company and will be required to make returns under the PAYE regulations to account for Income Tax and NICs.
H18. The figures relate to Income Tax, NICs, and Student Loan Repayments collected through PAYE due on earnings and other income from employment. The scope of these figures also includes tax due on occupational pensions taxed through PAYE.
H19. The random sample is selected using the former small and medium-sized enterprises customer classification and stratified on the basis of employer characteristics (defined in terms of the number of employees and whether the employer’s business is incorporated). Prior to ‘Measuring tax gaps 2020’ edition, we calculated the small business tax gap by first calculating the PAYE tax gap for small and medium-sized enterprises employers. This small and medium-sized enterprises estimate was then converted to a small business estimate using historical data on tax receipts that was available under both groupings.
H20. From ‘Measuring tax gaps 2020 edition’ the PAYE small business tax gap is calculated directly using small businesses only data for the tax year 2015 to 2016 and onwards. This is done by flagging and removing mid-sized businesses from the random sample to create a small business only sample. However, for historical years the conversion factor is still applied as the source data does not contain the information required for the identification of mid-sized businesses, therefore they cannot be removed.
Corporation Tax
H21. The Corporation Tax REP allows us to estimate the tax gap arising from incorrect Corporation Tax returns of small businesses. Results from the Corporation Tax REP are scaled up to the total number of live small businesses trader cases. In this context, ‘live’ excludes cases which are, for instance, dormant or dissolved. In addition to this, sample cases are excluded if the company has not submitted a return for the year of interest.
H22. For Corporation Tax, up to the tax year 2015 to 2016, the random sample was selected using the former small and medium-sized enterprises customer classification. From 2016 to 2017 the random sample is selected from the small business customer group from businesses which have been issued a notice to file a return.
H23. The REP data is used to directly calculate the Corporation Tax small businesses tax gap from the tax year 2016 to 2017 and onwards. For earlier years the REP data was collected under the former small and medium-sized enterprises population definition and the estimate of the small businesses tax gap was estimated by applying a conversion factor which was derived using historical data on tax receipts that was available under both groupings.
H24. From April 2013, we changed the sampling process to a stratified random sample, based on the size of annual trading turnover. This change allowed the Corporation Tax REP results to be weighted by the actual population of each stratum resulting in improved accuracy of the tax gap results.
H25. Due to a relatively small sample size and large natural variance in the levels of under-declared liabilities from year to year, a smoothing approach is used.
H26. From ‘Measuring tax gaps 2023 edition’ the rolling average methodology has been updated, bringing it in line with the other REP models. Previously, the rolling average was calculated by multiplying the rate of non-compliance in the latest year by the average value of non-compliance over the latest three years. The new method multiplies the rate of non-compliance in each of the latest three years by the corresponding year’s value of non-compliance and then calculates an average.
Data features
H27. The latest observed random sample for Self Assessment used in the ‘Measuring tax gaps 2025 edition’ estimates is for 2021 to 2022. From 2014 to 2015 approximately half of the sample was worked as a desk-based compliance check rather than the standard face to face approach before the move to a fully desk-based approach was implemented in the tax year 2016 to 2017. An internal evaluation of the effect of working REP cases as a desk-based compliance check as opposed to face to face was carried out and found no statistically significant evidence that it affected the outcome of the compliance check.
H28. In ‘Measuring tax gaps 2022 edition’ we postponed using the Self Assessment REP data for 2018 to 2019 due to increased uncertainties in the REP arising from different ways of working during the pandemic. Following a review by experienced caseworkers of the 2018 to 2019 and 2019 to 2020 REP we have established a compliance yield uplift and applied it to the data.
H29. The latest observed PAYE random sample is for 2023 to 2024. From 2015 to 2016, approximately half of the sample was worked as a desk-based compliance check rather than a face-to-face approach before the move to a fully desk-based approach was implemented in the year 2018 to 2019. An evaluation of the effect of working cases as a desk-based compliance check as opposed to face to face was carried out and found no statistically significant evidence that it affected the outcome of the compliance check.
H30. The latest observed Corporation Tax random sample is for 2021 to 2022. Both the 2019 to 2020 and 2020 to 2021 samples were originally split equally to evaluate the impact of working Corporation Tax REP cases as desk-based compliance check as opposed to the standard face to face approach. However, 2019 to 2020 and 2020 to 2021 Corporation Tax REP cases were worked as desk-based compliance check. This was due to the pandemic where face-to-face compliance checks were paused. From 2021 to 2022, samples are worked both desk-based and face-to-face based on the merits of the case.
Timing
H31. There are 2 factors which influence the timing of the latest available tax gap estimate for a particular type of tax return:
- delays inherent in the returns process; this varies according to the head of duty and is shown in Table H.4 below
- delays due to the complexity of some random compliance checks; it can take several years before sufficient random compliance checks relating to a particular tax year are settled to robustly report the results
Table H.4: Comparison of delays due to returns process
| REP | Delays due to returns process |
|---|---|
| Self Assessment | Individuals generally have until 31 January following the year of assessment to which the return relates to submit their return. Once the return is submitted, HMRC then has a further year in which to open a compliance check. |
| PAYE | None. PAYE reviews initially look at the records of the previous 12 months. |
| Corporation Tax | Companies have until a year after the end of their accounting period to submit their return. HMRC then has a further year in which to open a compliance check. |
H32. Due to the timing issues above, there are limitations in the availability of data for the most recent years. Firstly, estimates of tax gaps for Corporation Tax and Self Assessment are not available due to data lags. To present a more consistent picture of the scale of tax losses, projection factors have been applied to these estimates. The projections assume a constant percentage gross tax gap and use actual tax liabilities, non-payment and compliance yield from the relevant projected tax years. Currently, we are projecting for the 2 most recent years for both of these estimates.
H33. Using this approach ensures that our projections reflect changes to tax rates and taxable income/profits and assumes a stable rate of underlying compliance. We use the latest available data to project future years as this allows us to most effectively reflect recent policy and other changes that have a long-term impact on taxpayer behaviour. These projection factors are summarised below in Table H.5.
H34. Secondly, at the time of estimation, some compliance checks from earlier years’ REPs will still be ongoing. To estimate tax gaps for each year, it is necessary to make assumptions about the cases that are yet to be settled at the date the compliance check results are analysed. Where possible, caseworker forecasts are used. Where caseworker forecasts are not possible, we forecast for such compliance checks based on the results of settled compliance checks with similar durations.
H35. Finally, estimates for earlier years are revised from what has previously been published, because of using actual data for tax years we were previously projecting for and long-running cases settling for different amounts to what was previously forecasted.
Table H.5: Comparison of projection factors
| REP | Projection factors |
|---|---|
| Self Assessment | For the years after 2021 to 2022 where we do not have REP data, the latest available estimate is projected forward. The projections are made by keeping the percentage gross tax gap constant and using actual tax liabilities, non-payment and compliance yield for the relevant tax. |
| Corporation Tax | For the years after 2021 to 2022 where we do not have REP data, the latest available estimate is projected forward. The projections are made by keeping the percentage gross tax gap constant and using actual tax liabilities, non-payment and compliance yield for the relevant tax. |
| PAYE | No projection factor is required. |
Sources of error
H36. There are 2 main sources of error associated with the results of REPs which could result in the true values of the tax gaps differing from the estimates produced. These are:
- sampling variation in the data: the whole population is not subject to a compliance check, so even though the sample is designed to be representative, its characteristics may differ from the population purely by chance
- systematic uncertainty where the sample results consistently tend to under-report the true values for the population, or where the sample does not include the full population, for example those participating in avoidance
H37. We make an adjustment for one source of systematic uncertainty, which is non-detection of non-compliance. The REPs will not identify all incorrect returns or the full scale of under-declaration of liabilities, so estimates produced from the unadjusted results of the programmes would underestimate the full extent of the tax gap. We apply non-detection multipliers to the results of the REPs to account for this.
H38. We use different approaches to derive the non-detection multipliers used in our models. Our long-term approach has been to use multipliers derived from analysis by the Internal Revenue Service (IRS) in the United States. In recent years we have worked to develop new non-detection multipliers using the ‘Delphi’ approach and have so far introduced these for PAYE.
H39. More information about the Delphi approach and our plans to carry out a programme of development to introduce new non-detection multipliers in future editions of ‘Measuring tax gaps’ can be found in HMRC’s working paper ‘Non-detection multipliers for measuring tax gaps’.
H40. The multipliers are generally kept consistent year-on-year, however adjustments to this were made for Corporation Tax from ‘Measuring tax gaps 2023 edition’ as explained in paragraph H43. The size of the multipliers varies depending on the complexities of each tax regime and the type of non-compliance found; Table H.6 shows how these multipliers differ by each REP.
H41. We use different multipliers to estimate lower and upper bounds to show the full range of uncertainty in our estimates. This range is based on the 95% confidence intervals of the estimate which are then adjusted for non-detection. A multiplier of 1 is used for the lower bound estimate, assuming that all non-compliance has been detected during our random enquiries.
H42. Multipliers derived from the IRS are used in the Self Assessment tax gap. The IRS has previously tackled the problem of non-detection by developing its own range of ‘multipliers’. We applied the principles behind the IRS methodology to HMRC’s data to produce approximate multipliers for the UK for our central and upper estimates. The IRS approach is discussed in the paper Internal Revenue Service report — Tax Compliance. The IRS was able to undertake this analysis of non-detection because their REP samples covered upward of 50,000 cases — much higher than is feasible in the UK.
H43. Improvements in ways of working have been introduced in recent years for the Corporation Tax small businesses REP. Our review of this REP suggested that case workers were more likely to detect non-compliance in the most recent REPs, particularly from 2019 to 2020 and onwards, than in previous REPs. We have reduced the non-detection multiplier for the 2018 to 2019 and 2019 to 2020 Corporation Tax small businesses REPs accordingly. The non-detection multiplier has remained constant since 2019 to 2020.
Table H.6: Comparison of adjustments for non-detection
| REP | Multiplier for central estimate | Multiplier for lower estimate | Multiplier for upper estimate |
|---|---|---|---|
| Self Assessment (business) | 1.908 | 1.000 | 3.075 |
| Self Assessment (non-business) | 1.260 | 1.000 | 1.928 |
| PAYE | 1.260 | 1.000 | 1.520 |
| Corporation Tax (pre 2017 to 2018) | 1.457 | 1.000 | 1.914 |
| Corporation Tax (2017 to 2018) | 1.303 | 1.000 | 1.593 |
| Corporation Tax (2018 to 2019) | 1.225 | 1.000 | 1.515 |
| Corporation Tax (2019 to 2020 onwards) | 1.157 | 1.000 | 1.314 |
Validation
H44. As part of each year’s programme, HMRC conducts a validation exercise for a sample of cases. These cases are checked to confirm that the compliance check outcomes (for example, the amount of yield) have been recorded accurately. Any inaccuracies are corrected prior to calculation of the tax gap for that year. For MTG25, the exercise covered Self Assessment business and non-business cases.
Outliers
H45. Outliers are individual cases with large yield which are far removed from the yield of the other cases in the sample. Due to the nature of our samples, our estimates are particularly sensitive to extreme values. To ensure that these small number of cases do not have an undue influence on the tax gap calculation, their yield values are capped. This allows us to use all valid information while smoothing the year-on-year variability.
H46. Yield data is modelled using a representative statistical distribution. The final value used for each tax year is calculated as a 3-year moving average of the 99.85th percentile from this distribution, calculated based only on the results of years where the sample was stratified. For years before stratification, and years where a full 3 years of stratified results are not available, a value based on the last 3 complete stratified years is used.
H47. A specific capping value is calculated for each REP, including a separate value for Self Assessment business and non-business.
Deselections
H48. Cases in the REP are not worked for several reasons and this is done in a non-random way. This means that the cases which are not worked are likely to be systematically different from the cases that are worked. Cases which are not worked are called deselections or rejections depending at which stage of the production process the decision to not work the case was taken.
H49. To avoid biasing the sample we treat and include cases that are deselected from the sample but are still within the population of interest. If the individual or business has undergone a recent compliance check , we substitute the outcome of this earlier compliance check into the case. If no such previous compliance check exists, we assign a value based on the average yield and probability of being non-compliant in the taxpayer’s stratum.
Self Assessment compliance check data
H50. Operational compliance check data is used with the Self Assessment REP results to estimate the Self Assessment tax gap. For individuals not covered by the REP, operational compliance check data is used.
H51. HMRC operates a comprehensive system of targeted customer auditing that includes monitoring, carrying out risk assessments, enabling resourcing decisions to better direct compliance check towards the highest risk customers.
Data Issues
H52. There is a lag in the data available for the most recent years in Self Assessment inherent to the returns process. See paragraph H31 for more details. This has 2 main consequences:
- estimates of tax gaps for Self Assessment are not available for the latest years due to the lag in data available — to present a more consistent picture of the scale of tax losses, projection factors have been applied to the estimates for the Self Assessment compliance check data
- at the time of estimation, some compliance check were not closed so to estimate tax gaps for each year, it is necessary to make assumptions about the cases that were yet to be settled at the date the compliance check results are analysed
H53. To maintain the integrity of the time-series, we have created an illustrative estimate of the tax gap based on the total Self Assessment tax gap for the years prior to 2015 to 2016.
H54. The Delphi technique was used to derive specific non-detection multipliers for the operational compliance check data for Self Assessment. We use different non-detection multipliers depending on the perceived risk of the cases ranging from 1.5 to 1.7. More information about the Delphi approach and non-detection multipliers can be found in HMRC’s working paper: ‘Non-detection multipliers for measuring tax gaps’.
Methodology
H55. Operational compliance check data is available for the highest risk segments where there is significant compliance activity. Low risk segments where there is less compliance activity are covered by a REP. The remaining cases are estimated by creating an upper and lower bound by scaling the results from the highest and lowest risk segments to the population size and then adjusting by a non-detection multiplier. The gross tax gap estimate from the compliance check data is then the sum of the tax gap from the highest and lowest risk segments and the midpoint between the upper and lower bounds.
H56. There is no direct way of splitting the compliance check data between Self Assessment business, Self Assessment non-business and Self Assessment large partnerships. We split the tax gap between these groups by looking at the percentage of the population that falls into each of these groups and applying these percentages to the tax gap.
Tax gap calculation
H57. The methodology for the PAYE and Corporation Tax small business tax gaps combines the estimate of under-declared liabilities with the amount of non-payment. As some of the tax gap is recovered through HMRC compliance activity, this is subtracted to give the net tax gap.
H58. The flowchart below illustrates the series of model operations described above using symbols to represent each step of the process and contains a short description of the process steps to calculate the PAYE and Corporation Tax gap estimates.
H59. Both the PAYE small business net tax gap and the Corporation Tax small business net tax gap are calculated by multiplying the under-declared liabilities from incorrect returns with the multipliers for non-detection, adding non-payment and subtracting the yield from compliance activity.

H60. The methodology for the Self Assessment business and non-business tax gaps uses the combined estimate of under-declared liabilities from the REPs and the operational compliance check data.
H61. The flowchart below illustrates the series of model operations described above using symbols to represent each step of the process and contains a short description of the process steps to calculate the Self Assessment business and non-business net tax gap estimates.
H62. The Self Assessment business and non-business net tax gaps are both made up of 2 parts, the under-declared liabilities from the REP and the under-declared liabilities from the operational compliance check data. The under-declared liabilities from the REP and the compliance check data are multiplied by the United States-derived multipliers to account for non-detection. These values are then added together along with non-payment before the yield from compliance activity is subtracted from their total.

H63. The ranges which define the upper and lower estimates of the tax gap are based on the 95% confidence intervals of the estimate for under-declared liabilities from incorrect returns. These ranges are then adjusted for non-detection as described in Table H.6 above.
Non-payment
H64. For ‘Measuring tax gaps 2025 edition’ we improved the methodology for the estimate of non-payment for Corporation Tax, and Income Tax, NICs, and Capital Gains Tax in Self Assessment and PAYE, for tax years since 2018 to 2019. The new methodology is an estimate of eventual non-payment attributable to the year of tax debt creation. These methodological improvements do not extend back beyond 2018 to 2019.
H65. Prior to 2018 to 2019 non-payment refers to tax debts that are written off or remitted in a tax year by HMRC and result in a permanent loss of tax.
H66. As separate figures of non-payment are not available for just the taxpayers within the scope of the REPs, the amounts are split in proportion to the tax gap resulting from the relevant section of the populations.
Compliance yield
H67. The REPs provide an estimate of the tax gap due to incorrect returns. However, HMRC carries out a wider programme of compliance activity to identify and correct erroneous returns. To calculate the net tax gap, it is necessary to subtract the yield from this activity.
H68. The figures for yield are taken from HMRC’s systems for recording the outcomes of compliance checks and relate to cases settled during each year rather than compliance checks into returns relating to a specific tax year. Yield by year of settlement is used as a proxy due to the extended timeline for completing all the compliance activity related to the liabilities for a year. See ‘Chapter C: Tax gap and compliance yield’.
H69. The Self Assessment compliance yield values have been adjusted to take account of the impact of COVID-19 on the amount of yield settled in 2020 to 2021 and 2021 to 2022 and maintain consistency in the time-series. To maintain the assumption of using yield by year of settlement as a proxy for yield by year of liability, we have made an adjustment to displace the drop in settlement yield to the years we expect this to impact in terms of reduced tax liability. This change is only applied to Self Assessment where there is a material difference on the estimates, and our underlying methodology remains the same. No further adjustments have been applied to compliance yield data for 2022 to 2023 onwards.
Other estimates
Large employers operating a PAYE scheme
H70. Larger employers are not covered by the PAYE REP. An illustrative estimate is produced by assuming that the tax at risk will represent, over the long term, a similar proportion of liabilities to small businesses employers as identified in the results of the REPs. The estimated tax at risk is then adjusted to reflect compliance yield and non-payment.
H71. An adjustment to the estimate of the tax gap was made following on from the introduction of the PAYE Real Time Information (RTI) system, where information on payroll taxes is recorded more accurately and on a more frequent basis allowing HMRC to identify debts and act at an earlier stage than previously. This is done by estimating the impact of RTI on the tax gap estimates from the REP and applying this change to the estimate for the larger employers.
Large partnerships in Self Assessment
H72. An illustrative estimate has been produced for Self Assessment large partnerships by assuming that the tax at risk will represent a similar proportion of liabilities to all other Self Assessment taxpayers, as shown by the results of the Self Assessment REP.
H73. An adjustment is made to project a component of the Self Assessment large partnerships estimate for 2019 to 2020.
Wealthy
H74. To calculate the Self Assessment wealthy tax gap, we identify wealthy taxpayers in the compliance checks data and the Self Assessment REP data. We then apply the same methodology used to estimate the Self Assessment tax gap to the wealthy population to get the wealthy portion of the Self Assessment business and Self Assessment non-business tax gaps.
H75. The large partnerships tax gap is not measured directly and as such we cannot use data matching to find the wealthy portion of the large partnerships tax gap. Instead, we find the percentage of liabilities from large partnerships which comes from wealthy taxpayers and apply that percentage to the Self Assessment large partnership tax gap.
H76. The net tax gap is calculated by deducting compliance yield from the gross tax gap and adding non-payment.
Uncertainty rating
H77. We assign an uncertainty rating to tax gap components on a scale using the ratings ‘very low’, ‘low’, ‘medium’, ‘high’ to ‘very high’. This is done by assessing the model scope, the methodology used and the data underpinning the estimate. See ‘Chapter B: Accuracy and Reliability’ for further information.
Self Assessment business and non-business (individuals and small partnerships)
H78. The uncertainty rating for the Self Assessment business and non-business tax gap estimate is ‘medium’. The Self Assessment business and non-business model captures the majority of the tax base and its population, the stratified REP methodology is robust, and the REP data is reliable and suitable for purpose. Areas of uncertainty include the projections applied to account for years where we do not have REP data, the requirement to forecast the expected compliance yield for compliance checks that are still ongoing and the treatment of outliers.
H79. Additional uncertainty arises from the non-compliance which is missed or not fully investigated in a compliance check which we account for by applying a non-detection multiplier. A fixed multiplier is used and so our approach fails to mitigate against changes in HMRC’s approach to compliance checks and non-detection. Uncertainty in the non-detection multiplier also contributes to a wide interval between the upper and lower bounds. The rating is unchanged from ‘Measuring tax gaps 2024 edition’.
Self Assessment large partnerships
H80. The uncertainty rating for the Self Assessment large partnerships tax gap estimate is ‘very high’. This is unchanged from ‘Measuring tax gaps 2024 edition’. This rating is given as the model may not capture the appropriate tax base and population, the illustrative methodology is heavily assumption-based, and data may not be representative. Key areas of uncertainty include the omission of non-compliance specific to large partnerships and the assumption that large partnership taxpayers behave in the same way as the Self Assessment business and non-business taxpayers.
Corporation Tax small businesses
H81. The uncertainty rating for the Corporation Tax small businesses tax gap estimate is ‘medium’. This means that the model captures the majority of the tax base and its population, the stratified REP methodology is robust, and the REP data is reliable and suitable for purpose. Areas of uncertainty include the projections applied to account for years where we do not have REP data and it is necessary to forecast the expected compliance yield for compliance checks that are still ongoing. Additional uncertainty comes from the non-compliance which is missed or not fully investigated in a compliance check. This uncertainty is mitigated by the inclusion of a non-detection multiplier. The rating is unchanged from ‘Measuring tax gaps 2024 edition’.
PAYE small businesses
H82. The uncertainty rating for the PAYE small businesses tax gap estimate is ‘medium’. This means that the model captures the majority of the tax base and its population, the stratified REP methodology is robust, and the REP data is reliable and suitable for purpose. Areas of uncertainty include it being necessary to forecast the expected compliance yield for compliance checks that are still ongoing. Additional uncertainty arises from the non-compliance which is missed or not fully investigated in a compliance check. This uncertainty is mitigated by the inclusion of a non-detection multiplier. The rating is unchanged from ‘Measuring tax gaps 2024 edition’.
PAYE large businesses
H83. The uncertainty rating for the PAYE tax gap estimate for large business employers is ‘very high’. This means that the model may not capture the appropriate tax base and population, the illustrative methodology is heavily assumption-based and data may not be representative. Areas of uncertainty include the assumption that PAYE large businesses behave in the same way as PAYE small businesses. The illustrative estimate uses data from PAYE small businesses, assuming the tax at risk in large businesses will represent a similar proportion of liabilities to PAYE small businesses. This uncertainty rating is unchanged from ‘Measuring tax gaps 2024 edition’.
Chapter I: Estimates using risk-based enquiry programmes
I1. In ‘Measuring tax gaps 2020 edition’ we introduced methodologies using HMRC’s risk-based operational enquiry data to estimate the tax gap in the following areas:
- PAYE for mid-sized business employers
- Corporation Tax for mid-sized and large businesses
- Inheritance Tax
I2. Before ‘Measuring tax gaps 2020 edition’ the mid-sized businesses PAYE, large and mid-sized businesses Corporation Tax and Inheritance Tax gap estimates were all based on experimental methods. Using the methods described in this chapter, we now use data specific for these customer groups in our estimates. This means the scale of the gap is likely to be a more accurate estimate of the true non-compliance in the respective populations.
I3. The large businesses PAYE tax gap estimates remain illustrative and are described in Chapter H.
Risk-based estimates
I4. HMRC carry out risk assessments to determine when and how to enquire into cases where there is a risk that the taxpayer has not paid the correct tax. These enquiries can take many different forms, such as a Self Assessment tax enquiry, an Employer Compliance review, or a VAT audit. We may refer to risk-based enquiries as risks in this chapter.
I5. Unlike random enquiry programmes (see Chapter h), risk-based enquiries are not representative of the population and require statistical methods to extrapolate the results to the whole population as part of a tax gap calculation.
Extreme value methodology
I6. Extreme value methodology is a statistical technique that is used to understand data that is characterised by extreme outlier observations. An example of this would be where a small number of data points make up a large majority of the total value. This is known as the power law or 80-20 rule, where approximately 80% of the yield comes from 20% of enquiries.
I7. Extreme value methodologies have been used to estimate tax non-compliance by other tax gap analysts, for example, within the Canada Revenue Agency, and the Australian Tax Office. For further information go to the Canada Revenue Agency and the Australian Tax Office.
I8. Risk-based enquiry results from the populations studied in this chapter fit the extreme values assumptions; most of the value of non-compliance is concentrated in a small number of businesses/individuals.
I9. Data lying outside the extreme values regime fails to follow the power law and is removed by the implementation of a threshold cut-off. The remaining data is fitted to the power law model using an ordinary least squares regression.
I10. The number of businesses/individuals not subject to risk-based enquiries that might contribute to the tax gap is estimated by assuming the same proportion of above threshold risks as found in the risk-based enquiry population. These businesses are assumed to have a lower risk of non-compliance and unlikely to contribute large tax adjustments.
Tax gap calculation
I11. The higher the accuracy of the risking methods, the more accurate the extreme value results. We have taken a conservative assumption that the extreme value method may lead to an underestimate of the tax gap in some of our population groups where the risking procedures are more challenging and some higher yield risks may have been missed.
PAYE and Corporation Tax
I12. In the case of the PAYE tax gap for mid-sized businesses and the Corporation Tax gap for mid-sized and large businesses we use the results of the extreme value methodology for the lower bound estimate.
I13. For the upper bound estimate, the average tax gap as a percentage of liabilities for businesses not subject to risk-based enquiries is assumed to be the same as that for businesses in the risk-based enquiry population. This leads to an overestimate since these businesses were selected based on expected non-compliance.
I14. The net tax gap for these populations is then found as the average of the lower bound and upper bound results. The gross tax gap for these populations is then calculated as the net gap plus the compliance yield, minus non-payment.
Inheritance Tax
I15. In the case of the Inheritance Tax gap, the extreme value methodology is the central estimate. Since the ‘Measuring tax gaps 2021 edition’, the Inheritance Tax extreme value methodology was expanded to include liabilities arising from transfers of assets into and out of trusts, as well as charges that are due every ten years. As internal data on the total number of theoretically chargeable estates are not readily available for the most recent years being estimated, we project this figure using the number of deaths in a year. These data are published by the Office for National Statistics.
I16. Upper and lower bounds are produced alongside the central Inheritance Tax gap estimate. These account for uncertainty that arises from the forecasting of yield for risks that are unresolved and the goodness-of-fit calculated during the power law fitting process.
I17. The net tax gap is calculated by deducting compliance yield from the gross tax gap.
Data issues
I18. Operational audit data in a suitable form is not available for some earlier years. As such the tax gaps that have adopted this methodology have done so from the tax years 2013 to 2014 for Inheritance Tax, and 2014 to 2015 onwards for the Corporation Tax and PAYE tax gaps.
I19. For the Inheritance Tax gap the earlier years have been calculated by scaling the previously published data by the ratio between the old and new results, in the years both figures were available. For the Corporation Tax and mid-sized businesses PAYE tax gaps the previously published data from ‘Measuring tax gaps 2020 edition’ is kept static for earlier years.
I20. Compliance risks can take many years to resolve. For open risks it is necessary to forecast the expected compliance yield to calculate the tax gap. Previously we did this by matching all open risks to a similar closed case and using yield from closed risks in the model. For ‘Measuring tax gaps 2025 edition’ improvements have been made to how compliance yield for open risks is forecasted. For any open risk expected to close within the next 6 months or currently going through litigation, we have used caseworker assessment to forecast expected compliance yield. For all remaining open risks, we have continued to forecast as previously done.
I21. Differences between the forecast yield and actual yield may lead to revised tax gap estimates in subsequent publications, but the use of forecasting reduces the chance that these revisions are significant. The tax gap for more recent years is likely to be subject to larger revisions because a higher proportion of the compliance yield is estimated.
I22. Risks may also take several years to settle, and this is significant in the data for the Corporation Tax gap for more recent accounting periods. The use of projected data for these years ensures the chance of large revisions to these years is minimised. To minimise revisions to the large businesses Corporation Tax gap, in `Measuring tax gaps 2025 edition’, the compliance yield figures for the tax years from 2022 to 2023 have been projected based on the percentage of compliance yield to liabilities for 2021 to 2022. For ‘Measuring tax gaps 2025 edition’ the projection has been shortened from 5 years to 2 years.
I23. The yield collected in a risk is allocated to the accounting period the risk relates to. Risks can also be identified and not lead to any tax adjustment if the taxpayer is deemed to be compliant, meaning the risk will have been settled without any additional tax due. These are still included in our model as they are an important contribution to the overall picture of non-compliance in the population.
Sources of error
I24. There are 3 main sources of error associated with the results of these methodologies which could result in the true values of the tax gaps differing from the estimates produced. These are:
- systematic uncertainty where the results from the risk-based audits consistently tend to under-report the true values for the population, or where the sample does not include the full population, for example those participating in avoidance
- uncertainty arising from variations in the risk-based data due to different risking approaches
- inaccurate population numbers
I25. We make an adjustment for one source of systematic uncertainty, which is non-detection of non-compliance. Audits will not identify all incorrect returns or the full scale of under-declaration of liabilities, and so estimates produced from the unadjusted results of the programmes would underestimate the full extent of the tax gap. To account for this, we apply a non-detection multiplier to audit data to get a better reflection of what the true tax gap would look like.
I26. Before ‘Measuring tax gaps 2024 edition’, the Corporation Tax multiplier was based on US research from the Internal Revenue Service (IRS), which had been adjusted for the UK tax system, to account for non-detected non-compliance. Further details can be found in Chapter H ‘Estimates using random enquiry programmes‘.
I27. For ‘Measuring tax gaps 2024 edition’, we based the Corporation Tax non-detection multiplier on expert opinion, which involved HMRC colleagues reaching a consensus through a short questionnaire. This replaced the old non-detection multiplier used in both mid-sized and large businesses Corporation Tax gap. For ‘Measuring tax gaps 2025 edition’ we have continued to use the revised non-detection multiplier in both mid-sized and large businesses Corporation Tax gap between the tax years 2014 to 2015 and 2023 to 2024.
I28. For ‘Measuring tax gaps 2025 edition’, we based the mid-sized business PAYE non-detection multiplier on expert opinion, which involved HMRC colleagues reaching a consensus through a short questionnaire. This more bespoke non detection multiplier replaced the old non-detection multiplier used in ‘Measuring tax gaps 2024 edition’ which was based on small business non-detection. Further information on the multipliers used to calculate tax gap estimates can be found in HMRC’s working paper ‘Non-detection multipliers for measuring tax gaps’.
I29. For Inheritance Tax, we base the multiplier on expert opinion. This involved HMRC operational colleagues reaching a consensus through a short questionnaire, which was further quality assured by a wider stakeholder group. More information can be found in HMRC’s working paper.
I30. The non-detection multipliers currently used in the extreme value methodologies are shown below:
| Corporation Tax | PAYE | Inheritance Tax | |
|---|---|---|---|
| Non-detection multiplier | 1.225 | 1.3 | 1.7 |
I31. Data variations arising from changes to the success of the risk profiling used to obtain operational audit data has the potential to lead to changes in the tax gap estimate that may not be reflective of the real-world situation. An example would be a change to the success of the risking procedures.
I32. It is challenging to quantitively measure risking success, but we gain an understanding of this through discussions with business experts and adjustments to the model, particularly the use of the upper bound method.
I33. Population numbers are fairly static and well defined in the case of large businesses. The mid-sized population numbers are defined through HMRC internal databases and have increased in recent years; in ‘Measuring tax gaps 2025 edition’ some public bodies and charities are now captured in mid-sized businesses population. The Inheritance Tax population isn’t well defined, but it is approximated using the total number of estates above the nil-rate band and the number of charges due on trusts. Sensitivity analysis has been carried out that confirms that the population number is not a very sensitive input.
I34. The Inheritance Tax gap estimate includes an underestimate of tax theoretically due on offshore trusts. We have not yet been able to quantify the level of bias, as it is caused by limitations in the number of tax returns being filed.
Non-payment
I35. For ‘Measuring tax gaps 2025 edition’ we improved the methodology for the estimate of non-payment for Corporation Tax, and Income Tax, NICs, and Capital Gains Tax in Self Assessment and PAYE, for tax years since 2018 to 2019. The new methodology is an estimate of eventual non-payment attributable to the year of tax debt creation. These methodological improvements do not extend back beyond 2018 to 2019.
I36. Prior to 2018 to 2019 non-payment refers to tax debts that are written off or remitted in a tax year by HMRC and result in a permanent loss of tax.
Compliance yield
I37. The compliance yield for risk-based models is calculated as the total yield from closed risks plus the estimated compliance yield from open risks. Compliance yield in these models relates to a specific accounting period and therefore differs from compliance yield published in HMRC’s Annual Report and Accounts.
Uncertainty ratings
I38. We assign an uncertainty rating to tax gap components on a scale using the ratings ‘very low’, ‘low’, ‘medium’, ‘high’ to ‘very high’. This is done by assessing the model scope, the methodology used and the data underpinning the estimate. See ‘Chapter B: Accuracy and reliability’ for further information.
Large businesses Corporation Tax gap
I39. The uncertainty rating for the large businesses Corporation Tax gap estimate is ‘medium’. This means that the model captures the tax base and most forms of non-compliance. Areas of uncertainty arise from the projections applied to estimate the 2 most recent tax years and the sensitivity to changes in compliance activity which the compliance yield data is based on. This uncertainty rating is unchanged from the ‘Measuring tax gaps 2024 edition’.
Mid-sized businesses Corporation Tax gap
I40. The uncertainty rating for the mid-sized businesses Corporation Tax gap estimate is ‘medium’. This means that the model captures the tax base and most forms of non-compliance. Areas of uncertainty arise from the projections applied to estimate the 3 most recent tax year estimates and the sensitivity to changes in compliance activity which the compliance yield data is based on. This uncertainty rating is unchanged from the ‘Measuring tax gaps 2024 edition’.
Mid-sized businesses PAYE tax gap
I41. The uncertainty rating for the mid-sized businesses PAYE tax gap estimate is ‘medium’. This means that the model captures the tax base and most forms of non-compliance, as it uses reliable data although this is sensitive to year-on-year compliance activity and risking approaches. Areas of uncertainty arise from the projections applied to estimate the most recent tax year estimates and the sensitivity to changes in compliance activity, which the compliance yield data is based on. This uncertainty rating is unchanged from ‘Measuring tax gaps 2024 edition’.
Inheritance Tax gap
I42. The uncertainty rating for the Inheritance Tax gap estimate is ‘high’. This means that the model has fair coverage of the tax base and most forms of non-compliance. The extreme value methodology is the most suitable for the population but relies on highly sensitive assumptions and uses compliance data sensitive to year-on-year compliance activity.
I43. Areas of uncertainty include the projections applied to account for years where it is necessary to forecast the expected compliance yield for risks that are still ongoing. Uncertainty also arises from the non-detection multiplier values applied to compliance results to account for non-compliance which is missed or not fully investigated in an audit. The uncertainty rating is unchanged from ‘Measuring tax gaps 2024 edition’.
Chapter J: Other taxes
J1. The other taxes gaps include:
- Inheritance Tax gap (this is described in chapter I)
- Landfill Tax gap
- Other excise duties gap, which includes:
- Betting and gaming duties gap
- Cider and perry duties gap
- Spirit-based ready-to-drink beverage duties gap
- Wine duties gap
- Other taxes, levies and duties gap, which includes:
- Aggregates Levy gap
- Air Passenger Duty gap
- Climate Change Levy gap
- Customs Duty gap
- Digital Services Tax gap (introduced in tax year 2021 to 2022)
- Insurance Premium Tax gap
- Plastic Packaging Tax gap (introduced in tax year 2022 to 2023)
- Soft Drinks Industry Levy gap (introduced in tax year 2018 to 2019)
- Petroleum Revenue Tax gap
- Stamp Duty Land Tax gap
- Stamp Duty Reserve Tax gap
J2. With the exception of the Inheritance Tax gap, methodologies for ‘other taxes’ gaps are illustrative where we use the best available data, simple models and management assumptions to build an estimate of the tax gap.
J3. The Petroleum Revenue Tax gap is only estimated up until the 2014 to 2015 tax year. After this, the estimate was discontinued due to Petroleum Revenue Tax being zero-rated from 1 January 2016.
Stamp Duty Land Tax gap
Methodology
J4. The Stamp Duty Land Tax (SDLT) gap is an illustrative methodology and is estimated using a combination of management information and management assumptions.
Tax under consideration
J5. The SDLT gap is calculated from the amount of SDLT outstanding, referred to here as tax at risk (TAR). The following 4 components which contribute to the tax gap have been identified:
- TAR from SDLT avoidance cases being investigated
- SDLT avoidance unknown to the department
- SDLT reliefs that are improperly claimed
- SDLT not paid due to evasion and other associated losses
TAR from SDLT avoidance cases
J6. This reflects the TAR from cases being investigated by HMRC, largely relating to mass-marketed and other avoidance schemes. Additionally, we apply an assumption that HMRC can only recover 75% of the tax at risk involved in these cases.
SDLT avoidance unknown to the department
J7. It would be impossible for HMRC to know about every case of SDLT avoidance, because either the associated paperwork has not been completed, or because it has been deliberately falsified and not yet discovered, or for some other reason. Expert opinion has suggested that HMRC is likely to be aware of approximately 80% of all transactions involving SDLT where tax at risk has resulted. For this reason, a multiplier of 1.25 (100 / 80) has been used to ‘uplift’ the amount of known tax at risk to account for this.
Evasion
J8. This reflects a percentage of the total amount of SDLT receipts (as published by HMRC) not initially paid because of evasion. Internal discussions with subject matter experts suggests that this amounts to 1% of the published SDLT receipts each year, with around 50% of this recoverable in line with other non-avoidance activity.
Reliefs improperly claimed
J9. Improperly claimed reliefs take different forms and there are more than 30 different reliefs claimed for SDLT. All reliefs are taken into account for this calculation.
J10. Analysis of open enquiries and a series of pilot research projects suggest that up to 5% of these claims may be falsely claimed. Additionally, there is an assumption that HMRC recovers 10% of the tax at risk involved in these cases: this takes into account the large number of reliefs for which compliance work has not yet begun and the small number of cases open into those reliefs that have been targeted.
J11. The Stamp Duty Land Tax gap has revisions from 2018 to 2019. This is due to revisions to data on amount and counts of Stamp Duty Land Tax reliefs claimed, used to estimate the amount improperly claimed.
Other associated losses
J12. This reflects a percentage of the total amount of SDLT receipts (as published by HMRC) not initially paid due to other associated losses. Internal discussions with subject matter experts suggest that this amounts to 0.5% of the published SDLT receipts each year, with around 50% of this recoverable in line with other non-avoidance activity.
Exclusions from this methodology
J13. Estimates for years prior to 2011 to 2012 include the amount of SDLT avoided by the use of tax avoidance schemes. These were artificial structures solely constructed to avoid SDLT that the department was aware of. This was calculated by multiplying together the number of disclosures of tax avoidance schemes (DOTAS) schemes, the estimated tax under consideration each year and the estimated number of users of each DOTAS scheme. This is excluded from 2011 to 2012 onwards as no further DOTAS schemes related to SDLT have been revealed to the department.
J14. Estimates for years prior to 2015 to 2016 include threshold manipulation (another form of SDLT evasion). This occurred when a sale value of a property was artificially reduced to below a threshold in order to reduce the SDLT liability. Previously, SDLT was charged at a single rate based on the value of the total purchase price. From 4 December 2014, SDLT liabilities changed to incremental rates applied only to the portion of the purchase price that falls within each rate band. This significantly reduced the potential value of tax lost due to threshold manipulation. For this reason, estimates after this point do not include threshold manipulation.
Landfill Tax gap
Methodology
J15. The Landfill Tax gap is estimated using an illustrative methodology using a combination of modelling, proxy indicators and assumptions made in collaboration with HMRC’s operational experts. It uses HMRC, Environment Agency (EA) and publicly available data to estimate each component.
J16. From 1 April 2015, Landfill Tax was devolved to Scotland hence, since ‘Measuring tax gaps 2017 edition’, Scottish Landfill Tax is no longer in scope of this estimate. Landfill Tax attributable to Scotland is removed from the tax gap estimate by using the percentage of total UK Landfill Tax receipts attributable to Scotland.
J17. From 1 April 2018, Landfill Tax was devolved to Wales hence, since ‘Measuring tax gaps 2020 edition’, Welsh Landfill Tax is no longer in scope of this estimate. Landfill Tax attributable to Wales is removed from the tax gap estimate by using the percentage of total UK Landfill Tax receipts attributable to Wales.
Tax in scope
J18. Landfill Tax is due on waste disposed of at permitted landfill sites and at unauthorised waste sites as a disincentive to landfilling and to encourage better waste management. The tax gap measures the difference between the amount of Landfill Tax that should theoretically be paid when waste is disposed of at permitted landfill sites and unauthorised waste sites, and the amount that is actually paid.
J19. The methodology has been updated since ‘Measuring tax gaps 2020 edition’ to include unauthorised waste sites. This became taxable from 1 April 2018 so is included in publications for tax years 2018 to 2019 onwards. Tax was not due on unauthorised waste sites prior to this date, so has been excluded from our methodology for earlier years up to and including 2017 to 2018.
Tax under consideration — under-declaration
J20. Under-declared waste is estimated in two ways and averaged to calculate a central estimate.
J21. In the first method, a trend line is fitted to HMRC data on taxable tonnes over time, then expected and actual tonnages of waste are compared. The estimate is refined to take account of the increase in diversion of waste away from landfill in recent years to incineration and export of refuse derived fuel. We assume nearly all of this diverted waste is taxable at the standard rate if sent to landfill.
J22. After these adjustments, the tax under consideration is estimated by applying the tax rates at the same composition as declared taxable waste. The ratio of standard rate to lower rate has changed over time with it becoming roughly 50:50 in recent years.
J23. In the second method, a proxy indicator is used to estimate under-declaration. This assumes that all landfill site operators have under-declared taxable waste by 5% per year, and that this under-declared amount should be taxed at the standard rate.
Tax under consideration — misclassification
J24. There are two rates of Landfill Tax, standard and lower rate. A trend line is fitted to HMRC published statistics on lower rated tonnes declared over time. Expected tonnages of lower rate waste is then compared with declared lower rate waste. Declared lower rate waste shows a trend towards increasingly larger amounts of lower rated waste going to landfill in recent years. Some of this is expected due to changes in how waste is diverted away from landfill towards other forms of waste management.
J25. We assume 25% of the difference between expected and declared lower rated waste constitutes the tax base under consideration. The tax under consideration is then the difference between the standard and lower rates of waste on this tonnage.
Unauthorised waste sites
J26. The estimated tax gap is based on EA data on estimated tonnage for known illegal waste sites. This data is provisional while the EA undertake a quality review of the estimated tonnage for the largest sites, which may result in revisions to future estimates.
J27. Sites that gained exemption or the appropriate permit have been excluded from our calculation, as have sites that have evidence of being stopped, regulated or cleared before 1 April 2018. Tonnage from active sites included in a given tax year will be excluded from subsequent tax years to avoid double counting. The standard rate of Landfill Tax has been applied to the remaining sites to calculate the tax gap for England. The estimate is uplifted to account for Northern Ireland (NI), which is not covered by EA data. This is done by applying the ratio of total tax liabilities in England and NI to the estimate for unauthorised waste sites tax gap in England.
Tax gap calculation
J28. The gross tax gap estimate is defined as the sum of under-declared waste, misclassified waste and waste from unauthorised waste sites. Some of the gross tax gap is recovered through HMRC compliance activity. As compliance yield can vary substantially year on year, this is smoothed using a 3-year moving average and then subtracted from the gross gap to give the net tax gap.

Other excise duties
J29. The other excise duties gap includes:
- Betting and gaming duties
- Cider and perry duties
- Spirit-based ready-to-drink beverage duties
- Wine duties
J30. The other excise duties gap is based on an illustrative method, whereby a proxy indicator for the scale of revenue losses across other excise duties has been produced by estimating the weighted average percentage of tax gaps for similar taxes each year and applying this to receipts in ‘other excise duties’.
J31. The average percentage revenue losses should not be considered estimates of the true percentage losses across betting and gaming, cider and perry, spirits-based ready-to-drink beverages and wine duties, as this is unknown. Many of these taxes are very different from one another in nature and are therefore subject to different rules. The true other excise duties gaps are therefore likely to vary across the duties.
Other taxes, levies and duties
J32. The other taxes, levies and duties gap includes:
- Aggregates Levy
- Air Passenger Duty
- Climate Change Levy
- Customs Duty
- Digital Services Tax
- Insurance Premium Tax
- Plastic Packaging Tax
- Soft Drinks Industry Levy
J33. The ‘other taxes, levies and duties’ gap is based on an illustrative method, whereby a proxy indicator for the scale of revenue losses across ‘other taxes, levies and duties’ has been produced by estimating the weighted average percentage of the overall tax gap each year and applying this to receipts.
J34. The average percentage revenue losses should not be considered estimates of the true percentage losses across Aggregates Levy, Air Passenger Duty, Climate Change Levy, Customs Duty, Digital Services Tax, Insurance Premium Tax, Plastic Packaging Tax and Soft Drinks Industry Levy, as this is unknown. Many of these taxes are very different from one another in nature and are, therefore, subject to different rules. The true tax gaps are therefore likely to vary across the taxes.
Chapter K: Avoidance and hidden economy
Avoidance
Data sources
K1. This section describes estimates of the avoidance tax gap for Income Tax, NICs, and Capital Gains Tax. The avoidance tax gap is estimated using information that HMRC collects on tax avoidance schemes and records on its management information system. This includes avoidance schemes for individuals, trusts, partnerships and employers. The information that HMRC collects relates to ‘disclosed’ and ‘undisclosed’ schemes.
K2. ‘Disclosed’ schemes are arrangements (including any scheme, transaction or series of transactions) that will or are intended to provide the user with a tax advantage when compared to a different course of action and, under tax legislation, must be disclosed to HMRC. You can find more information about disclosure of tax avoidance schemes (DOTAS) on GOV.UK.
K3. ‘Undisclosed’ schemes are arrangements identified by HMRC but not disclosed under DOTAS legislation.
K4. For schemes disclosed under DOTAS, information is captured during the following process:
- promoters of avoidance schemes that are covered by the avoidance disclosure rules must disclose any new schemes to HMRC when they are made available to potential users
- disclosures must contain sufficient detail for HMRC tax specialists to understand how the scheme works
- for each disclosure HMRC issues a scheme reference number to the promoters, and taxpayers who participate in the scheme are required to notify HMRC of the reference number on their tax return (described here as a ‘notification’)
K5. When reviewing both ‘disclosed’ and ‘undisclosed’ avoidance schemes, tax specialists record an estimate of the ‘tax under consideration’ based on the relevant information relating to these ongoing enquiries. Any additional tax (‘compliance yield’) that is collected following completed enquiries is also recorded.
K6. Detailed taxpayer-level data on avoidance schemes is available for large businesses and wealthy individuals. This enables comparison of the tax under consideration and compliance yield for an individual scheme user.
Methodology
K7. For ‘Measuring tax gaps 2025 edition’, we have introduced a new established methodology in the avoidance tax gap. This replaces an experimental methodology used in ‘Measuring tax gaps 2024 edition’. This new methodology is explained below:
- the new methodology takes internal data on avoidance schemes at the user level and identifies the tax at risk along with any compliance yield from closed compliance checks
- the tax at risk is adjusted using the change in user numbers in 2022 to 2023 and 2023 to 2024
- we apply a non-detection multiplier to tax at risk
- the tax gap is estimated by subtracting compliance yield from estimated tax at risk
K8. For each individual scheme user, a tax at risk estimate is derived based on several criteria to produce a more accurate estimate of the total tax at risk in the avoidance population compared to previous publications where estimates would be derived at the scheme level.
K9. The compliance yield is the total yield from closed cases plus estimated compliance yield from open cases. Compliance yield in this model relates to a specific accounting period and therefore differs from compliance yield published in HMRC’s Annual Report and Accounts.
K10. In the tax years 2022 to 2023 and 2023 to 2024 the number of individual scheme users is uplifted in line with past user number increases to account for a time-lag in new users being identified. The compliance yield for those years is then adjusted by the change in tax at risk.
K11. For ‘Measuring tax gaps 2025 edition’, we have based the avoidance tax gap non-detection multiplier on expert opinion, which involved HMRC colleagues reaching a consensus through a short questionnaire. Further information on the multipliers used to calculate tax gap estimates can be found in HMRC’s working paper ‘Non-detection multipliers for measuring tax gaps’. The non-detection multiplier used for ‘Measuring tax gaps 2025 edition’ is shown below:
| Avoidance | |
|---|---|
| Non-detection multiplier | 1.05 |
Data quality
K12. The main source of error in these estimates is that HMRC may not identify all avoidance schemes — which may lead to an underestimation of the tax gap which cannot be quantified. A non-detection multiplier has been added but this will only account for missed yield when conducting compliance checks, as in other tax gaps, and not schemes that have not been identified.
K13. As in previous publications, Corporation Tax avoidance for large business groups is excluded from these calculations to avoid double-counting with the separate avoidance estimate for these businesses; any re-classification of users following more accurate information would lead to revisions of the Corporation Tax avoidance estimate.
K14. A time lag for the input of data causes more uncertainty in the tax years 2022 to 2023 and 2023 to 2024; to account for this we have uplifted the user numbers and their total tax at risk in line with changes observed in previous years to minimise future revisions.
K15. The data on avoidance schemes are reviewed by HMRC analysts for consistency and accuracy. Over time, as the scope, quality and quantity of the data improves, HMRC will seek to improve the avoidance tax gap estimates.
Uncertainty rating
K16. We assign an uncertainty rating to tax gap components on a scale using the ratings ‘very low’, ‘low’, ‘medium’, ‘high’ to ‘very high’. This is done by assessing the model scope, the methodology used and the data underpinning the estimate. See ‘Chapter B: Accuracy and Reliability’ for further information.
K17. The uncertainty rating for the avoidance tax gap is ‘high’. Confidence in the model is increased from ‘Measuring tax gaps 2024 edition’ as this methodology is underpinned by simpler assumptions than the previous methodology. The quality of the data is still uncertain due to several factors and there is no assumption for any avoidance schemes not captured in the database. The rating of ‘high’ is changed from the rating of ‘very high’ in ‘Measuring tax gaps 2024 edition’.
Hidden economy
K18. The hidden economy has been considered in academic literature to include three forms of activities: legal economic activities (such as undeclared casual work), illegal economic activities (such as drug dealing or prostitution) and home production (including subsistence farming or producing goods for own consumption). The Hidden Economy Survey Wave 2 (HESW2) commissioned by HMRC in 2022 focuses on the first of these. This was the second survey conducted after the Hidden Economy Survey (HES) in 2015.
Moonlighters
K19. Moonlighters are defined as individuals who are employees in their legitimate occupation but do not declare earnings from other sources of income.
K20. The methodology for moonlighters is split into an earned income and unearned income tax gap. Earned income refers to individuals whose undeclared source of income is from employment. Unearned income refers to individuals whose undeclared source of income is not from employment but from sources such as lettings or interest.
K21. The earned and unearned income tax gap have separate methodologies. We add together the 2 estimates to calculate the moonlighters tax gap.
K22. To calculate the earned income estimate, data from both Hidden Economy Surveys is used. The first survey was commissioned by HMRC in 2015 to understand the nature of the hidden economy and the characteristics of those involved. For more information on the 2015 Hidden Economy Survey, go to GOV.UK. A new survey was published in 2023 which has been used for the estimates in tax years 2021 to 2022 and 2022 to 2023. Data on prevalence and income from hidden economy activities was captured as part of this research. In total, 9,640 respondents were surveyed in 2015 to 2016, while 5,538 people were surveyed in 2021 to 2022.
K23. The estimate for unpaid tax on moonlighters’ earned income from the survey samples is calculated by subtracting the tax paid on declared income from the tax that would have been due on their earnings if they had declared all their income. This covers Income Tax and NICs with allowances made for whether the hidden economy activity in question would be classified as self-employment or employment. An allowance for under-reporting of income is also made in line with academic literature.
K24. The sample estimate is then grossed up to the total population by using the prevalence rates of moonlighters with earned income in the population.
K25. A time series for the moonlighters’ earned income tax gap between 2005 to 2006 and 2014 to 2015 was created by projecting our estimates using the HES in line with Income Tax and NICs policy measures, based on the Office for Budget Responsibility’s certified policy costings. Since ‘Measuring tax gaps 2024 edition’, we have fixed the back-series between 2005 to 2006 and 2014 to 2015 as recent policy measure changes recently do not impact those years.
K26. We smooth between the survey derived values for the years 2015 to 2016 and 2021 to 2022 which causes a consistent downwards trend. We project the 2021 to 2022 value forwards using an index based on the impact of Income Tax policy changes on receipts using the Office for Budget Responsibility’s certified costings estimates.
K27. The tax gap for moonlighters’ unearned income covers those individuals who have additional sources of income that are not from employment. Some of these sources of income would therefore require them to submit a Self Assessment return to supplement their normal tax payment through PAYE.
K28. The sources of income covered by unearned income are lettings, interest, capital gains on property, chargeable events, Individuals Savings Accounts (ISAs) and secondary income (for example, activities such as hobbies or online selling that are not regular enough to be considered employment).
K29. It is not necessary for most taxpayers to submit a Self Assessment tax return where all tax liabilities are withheld at source. For example, employment income where tax is deducted under PAYE. However, there are risks within this population, for example due to taxpayers not informing HMRC about sources of income, especially where they may exceed tax-free allowances. If a Self Assessment tax return should have been completed, then: lettings, interest, ISA income and chargeable events would be subject to Income Tax; capital gains on property would be subject to Capital Gains Tax; and secondary income would be subject to Income Tax and NICs.
K30. HMRC has used data matching of administrative data and third-party information for tax years 2014 to 2015 and 2019 to 2020 to measure the extent to which taxpayers fail to declare these additional sources of unearned income accounting for relevant tax allowances, with an estimate of additional tax due being calculated from the identified undeclared income. Third-party data matched with administrative tax records includes rental deposit schemes, and bank and building society interest declarations. Because of the large amount of data involved in this exercise, data matching is only conducted on a representative sample of the population already in PAYE. The results are thereafter grossed up from the sample to produce an estimate of the overall tax gap from moonlighters’ unearned income.
K31. We smooth between the years 2014 to 2015 and 2019 to 2020 which causes a consistent downwards trend. We project the 2019 to 2020 value forwards using an index based on the impact of Income Tax, NICs, and Capital Gains Tax policy changes on receipts using the Office for Budget Responsibility’s certified costings estimates.
K32. For example, we project lettings income in line with Income Tax receipts over time. We take the lettings data-matching estimate for 2019 to 2020 and multiply it by a time series of Income Tax receipts, based on Income Tax policy changes from 2001 to 2002 and 2023 to 2024. This creates a time series of the tax gap for unearned moonlighters based on policy changes over time. We project the 2014 to 2015 value back using the same method.
K33. The limitations associated with the results of this exercise relate to the coverage of the third-party data used to establish evidence of additional undeclared income. Coverage varies across different sources of income, being especially reliable for lettings and interest income, whereas it is less reliable for the remaining sources identified. Additionally, there are other sources of income that could not be investigated due to unavailability of data. The resulting estimate should be interpreted broadly as a lower limit for the true scale of the tax gap relating to this group of taxpayers.
K34. This approach allows the projections to account for changes in both tax rates and the tax base over time. For example, increases in the personal allowance reduce the potential tax revenue from hidden economy activities, all else being equal.
Ghosts
K35. Ghosts are defined as individuals who do not declare any of their income to HMRC, be it earned or unearned.
K36. Data from the 2 surveys on the hidden economy is used to estimate the ghosts tax gap. See the moonlighters section beginning at paragraph K20 for details.
K37. The estimate for unpaid tax on ghosts’ income from the survey sample is calculated by applying the relevant tax rate to the undeclared income estimated from the survey observations. This covers Income Tax and NICs, with allowances made for whether the hidden economy activity in question would be classified as self-employment or employment. An allowance for under-reporting of income is also made in line with academic literature.
K38. This sample estimate is then grossed up to the total population by using the prevalence rates of ghosts in the population. These prevalence rates are obtained from the HES for 2014 to 2015 and HESW2 for 2019 to 2020. These include weighting for non-response so that the prevalence rates are representative of the overall population.
K39. As with moonlighters, a time series for the ghosts tax gap estimate was created by using an index based on changes in tax policy over time.
Uncertainty rating
K40. We assign an uncertainty rating to tax gap components on a scale using the ratings ‘very low’, ‘low’, ‘medium’, ‘high’ to ‘very high’. This is done by assessing the model scope, the methodology used and the data underpinning the estimate. See ‘Chapter B: Accuracy and reliability’ for further information.
K41. The uncertainty rating for the hidden economy tax gap estimate relating to Income Tax, NICs, and Capital Gains Tax for moonlighters is ‘high’. This means that the tax base may not be fully captured. For the tax base we do cover, the model uses the 2 surveys from 2015 to 2016 and 2021 to 2022 respectively and estimates a lower limit. Areas of uncertainty include the low coverage of moonlighter income sources and the lack of independent moonlighter data sources. This uncertainty rating is unchanged from ‘Measuring tax gaps 2024 edition’.
K42. The uncertainty for the hidden economy tax gap estimate relating to Income Tax, NICs, and Capital Gains Tax for ghosts is ‘very high’. This means that the tax base may not be fully captured. For the tax base we do cover, the model uses the 2 surveys from 2015 to 2016 and 2021 to 2022 respectively and estimates a lower limit. Areas of uncertainty include the potential underestimate of the tax gap, due to the limited coverage of the hidden economy ghost population. This uncertainty rating is unchanged from ‘Measuring tax gaps 2024 edition’.
Chapter L: Tax gap by customer group and behaviour
Tax gap by customer group
L1. HMRC collects tax from millions of individuals and from businesses of all sizes. To help us do this, we segment our customers into five groups so we can identify their needs and risks more accurately and tailor our responses accordingly.
L2. Tax gap measurements are aligned with these customer groups:
- individuals
- wealthy
- small businesses
- mid-sized businesses
- large businesses
L3. A separate tax gap estimate for criminals is also published. HMRC deals with fraud by using civil fraud investigation procedures where necessary. We reserve our criminal investigation powers for cases where HMRC needs to send a strong deterrent message, or where the conduct involved is such that only a criminal sanction is appropriate.
L4. You can read about simplification, administration and reform of tax
Individuals
L5. Individuals are by far our largest customer group. There are around 35 million people liable to pay tax through PAYE and Self Assessment. In 2023 to 2024, they were defined as having incomes below £200,000 and assets below £2 million in each of the last 3 years.
Wealthy
L6. Wealthy individuals often have complex tax affairs covering multiple taxes. There are around 850,000 wealthy individuals. In 2023 to 2024, they were defined as having incomes of £200,000 or more, or assets equal to or above £2 million in any of the last 3 years.
Small businesses
L7. Small businesses represent approximately 95% of businesses in UK. There are around 5.2 million small businesses. In 2023 to 2024, they were defined as having turnover below £10 million and typically fewer than 20 employees.
Mid-sized businesses
L8. Mid-sized businesses make up approximately 5% of UK businesses, but some are growing rapidly, making their tax affairs increasingly complex. There are around 340,000 mid-sized businesses. In 2023 to 2024 they were defined as having turnover between £10 million and £200 million, or typically 20 or more employees.
Large businesses
L9. Large businesses represent around 2,000 of the largest and most complex businesses. In 2023 to 2024, they were broadly defined as having turnover exceeding £200 million or £2 billion in assets, but we look at other factors such as complexity, level of risk and global mobility.
Tax gap by behaviour
L10. The tax gap is composed of a range of customer behaviours:
- avoidance
- criminal attacks
- error
- evasion
- failure to take reasonable care
- hidden economy
- legal interpretation
- non-payment
L11. The tax gap breakdown by behaviour is calculated using management information, assumptions and expert judgement combined with projections from historical data. The resulting estimates are subject to uncertainty which cannot be quantified. The estimates provide broad indicators of the behaviours contributing to the tax gap. They are illustrative and may not fully reflect how behaviours are changing over time.
L12. In ‘Measuring tax gaps 2023 edition’ we updated some assumptions used to estimate the behavioural breakdown of the tax gap. We updated some of the behaviour models that previously relied solely on historic fixed assumptions, replacing these with a combination of random enquiry programme customer behaviour data and operational expertise insight. These methodological improvements based on the latest data and operational insight do not extend back to 2005 to 2006.
L13. For ‘Measuring tax gaps 2025 edition’ we improved the methodology for the estimate of non-payment for Corporation Tax and Income Tax, NICs, and Capital Gains Tax in Self Assessment and PAYE for tax years since 2018 to 2019. The new methodology is an estimate of eventual non-payment attributable to the year of tax debt creation. This aligns to the VAT non-payment methodology introduced in ‘Measuring tax gaps 2023 edition’. These methodological improvements do not extend back beyond 2018 to 2019.
L14. We have also made a change to our methodology for the avoidance tax gap estimate for Income Tax, NICs, and Capital Gains Tax and revised our time-series back to 2015 to 2016, in addition to updating the methodology for avoidance and legal interpretation in the large businesses Corporation Tax gap.
Avoidance
L15. Avoidance involves bending the tax rules to try to gain a tax advantage that Parliament never intended. It often involves contrived, artificial transactions that serve little or no purpose other than to produce a tax advantage. It involves operating within the letter but not the spirit of the law.
L16. Some forms of base erosion and profit shifting (BEPS) are included in the tax gap where they represent tax loss that we can address under UK law.
L17. The tax gap does not include BEPS arrangements that cannot be addressed under UK law and that will be tackled multilaterally through the OECD. The OECD defines BEPS as ‘tax planning strategies that exploit gaps and mismatches in tax rules to make profits disappear for tax purposes or to shift profits to locations where there is little or no real activity but the taxes are low resulting in little or no overall corporate tax being paid’.
L18. The avoidance tax gap estimates reflect the laws that were in place at the time and do not include any subsequent changes to the tax law to prevent further use of avoidance.
L19. Tax avoidance is not the same as tax planning. Tax planning involves using tax reliefs for the purpose for which they were intended. For example, claiming tax relief on capital investment, saving in a tax-exempt ISA or saving for retirement by making contributions to a pension scheme are all forms of tax planning.
Criminal attacks
L20. Organised criminal groups undertake co-ordinated and systematic attacks on the tax system. This includes smuggling goods such as alcohol or tobacco, VAT repayment fraud and VAT missing trader intra-community fraud.
Error
L21. Errors result from mistakes made in preparing tax calculations, completing returns or in supplying other relevant information, despite the customer taking reasonable care.
Evasion
L22. Tax evasion is an illegal activity where registered individuals or businesses deliberately omit, conceal or misrepresent information in order to reduce their tax liabilities.
Failure to take reasonable care
L23. Failure to take reasonable care results from a customer’s carelessness and/or negligence in adequately recording their transactions and/or in preparing their tax returns. Judgments of ‘reasonable care’ should consider and reflect a customer’s knowledge, abilities, and circumstances.
Hidden economy
L24. The term “hidden economy” refers to sources of taxable economic activity that are entirely hidden from HMRC. It includes businesses that are not registered for VAT, individuals who are employees in their legitimate occupation, but do not declare earnings from other sources of income (moonlighters) and individuals who do not declare any of their income to HMRC, whether earned or unearned (ghosts).
L25. For tax gap behaviours, we treat the hidden economy and tax evasion as follows:
- hidden economy — where an entire source of income is not declared
- tax evasion — where a declared source of income is deliberately understated
Legal interpretation
L26. Legal interpretation losses arise where the customer’s and HMRC’s interpretation of the law and how it applies to the facts in a particular case result in a different tax outcome, and there is no avoidance. Specifically, this includes the interpretation of legislation, case-law, or guidelines relating to the application of legislation or case-law. Examples include categorisation such as an asset for allowances or VAT liability of a supply, the accounting treatment of a transaction, or the methodology used to calculate the amount of tax due as in transfer pricing, or VAT partial exemption.
Non-payment
L27. For VAT, Corporation Tax, and Income Tax, NICs, and Capital Gains Tax in Self Assessment and PAYE, for tax years since 2018 to 2019, non-payment is an estimate of eventual non-payment attributable to the year of tax debt creation. For years prior to 2018 to 2019, non-payment refers to the tax year in which tax debts are written off by HMRC and result in a permanent loss of tax.
L28. For all other taxes, non-payment is estimated using management information, assumptions and expert judgement combined with projections from historical data.