Greater London Authority: London Building Stock Model 2
Key information about London's properties, drawn from a range of sources and enhanced by modelling with the purpose of informing energy and housing programmes.
Tier 1 Information
Name
London Building Stock Model 2
Description
A Machine Learning tool that predicts missing/conflicting information (incl. heating type, insulation, etc.) about London’s properties from a range of open and commercial sources. Key information about London’s properties is needed to inform the city’s housing improvement programmes. These programmes have benefits including reducing our carbon emissions and also tenants’ energy bills. Unfortunately, existing information about properties only covers about half of the housing stock and so we are combining data from a wide range of open and commercial sources along with using machine learning to predict missing values and deal with conflicting information - with the final output being a sharable, complete, clean and consistent dataset.
Website URL
Contact email
Tier 2 - Owner and Responsibility
1.1 - Organisation or department
Greater London Authority
1.2 - Team
City Intelligence Unit
1.3 - Senior responsible owner
Senior Manager - City Data
1.4 - External supplier involvement
Yes
1.4.1 - External supplier
Applied Data Science Partners (ADSP)
1.4.2 - Companies House Number
10375946
1.4.3 - External supplier role
ADSP took some of our initial data modelling and applied it to a full set of variables. As well as providing a data output, they also investigated the best order in which to predict the variables.
Modelling work then returned to the in-house GLA data scientists to produce the first release of the outputs.
1.4.4 - Procurement procedure type
restricted’ - shortlist directly approached from a long list provided by Crown Commercial Services.
1.4.5 - Data access terms
Temporary access to Ordnance Survey data was granted (for the duration of the contract). However, most other input data was ‘open data’, including Energy Performance Certificates and Census data.
Tier 2 - Description and Rationale
2.1 - Detailed description
The tool uses a machine learning model, run on cloud infrastructure by data scientists and subject experts at the GLA. The best outputs are then shared with local authority officers and their contractors through a web-based interactive data explorer and API. The model uses a particular snapshot of input data (from early 2024), however, the plan is to run it monthly, to keep the outputs up to date.
The main modelling task is to fill in gaps in the data (typically where an Energy Performance Certificate isn’t available or is incomplete). The current model uses sequential target prediction and works its way through the variables in a particular order using the results of previous variables in subsequent modelling.
At key points, the models are ‘constrained’ to other data (for instance, the distribution of renters v owner occupiers in each neighbourhood from the Census) or London-level distributions from the British Housing Survey.
2.2 - Scope
The output from the tool has a number of purposes:
- to help people who are designing retrofit programmes understand the overall scale of activity needed and also where concentrations of properties with similar age, construction and ownership occur, providing economies of scale for double glazing, insulation or heat pump programmes.
- inform strategic plans (such as Local Area Energy Plans) and City-level monitoring of progression along the pathway to net zero carbon emissions
- act as a core linking dataset for London’s building stock, supporting other programmes, for instance, property-level monitoring of energy use by Internet of Things sensors
2.3 - Benefit
The main benefit is to provide complete coverage of London’s building stock, allowing better informed decisions to be made. These decisions help reduce carbon emissions and energy bills.
It will also allow policy makers to take the results of pilots and trials in particular building types and estimate the impact if they were rolled out to all buildings of that type.
2.4 - Previous process
The previous London Building Stock Model was built for the GLA by UCL in 2020 based on data from 2017. Whilst the outputs provided to the GLA have proved useful, the GLA wants to update this model (v2) and bring the modelling work in-house to allow us to: - update the outputs on a regular basis, making the best use of new data sources, published since the original work - fully understand and manage the uncertainties and assumptions, iterating and improving the modelling over time - develop different outputs, with clear lineage back to the different input datasets to maximise the range of organisations able to benefit from the work
2.5 - Alternatives considered
The main alternatives consist of other proprietary algorithmic models (including UCL’s). This approach would lead to restrictions on the GLA’s ability to share model outputs widely amongst London’s network of social landlords and specialist installers. There would also be less transparency about the assumptions and accuracy of predictions. Many of the proprietary outputs only cover some of the 21 variables.
The relationships between the different variables (for instance: age, wall type and EPC rating) are very complex and do not lend themselves to manual processes to fill in missing values.
Tier 2 - Decision making Process
3.1 - Process integration
The tool is trained on known property data (roughly 50% of London’s properties) and then used to predict values for the rest of the housing stock (where some information is already known, such as type of property, land ownership, etc). The tool finds the patterns and relationships in the data and then creates an output.
The output is then used by experienced officers and partners to develop programmes of work and decide priorities. As such, the algorithmic tool doesn’t make recommendations.
3.2 - Provided information
The key output is a table with a record for all 3.8m residential properties and values for each of the 21 variables. Each values is flagged as to it’s source (for instance EPC, modelled, etc).
A report showing the distribution of key variables is provided, along with the performance of the model for each variable (e.g. 82% accuracy).
3.3 - Frequency and scale of usage
The intention is to run the model on a regular basis. Over 200,000 new EPCs are lodged each year for London and new addresses released daily, therefore new input data becomes available which will improve the model’s outputs. The frequency is to be confirmed, but might be monthly or quarterly.
3.4 - Human decisions and review
The development of the model has had human review at several points. This has included sense checking of the logic, input from subject experts on the datasets to be used and then checking of output data.
3.5 - Required training
The model is run by experienced data scientists working with data engineers. The users of the outputs are subject matter experts and people with good local knowledge and so don’t require training in the use of the outputs. However, descriptions of the variables will be shared, along with the methodology and assumptions used by the GLA.
3.6 - Appeals and review
N/A
Tier 2 - Tool Specification
4.1.1 - System architecture
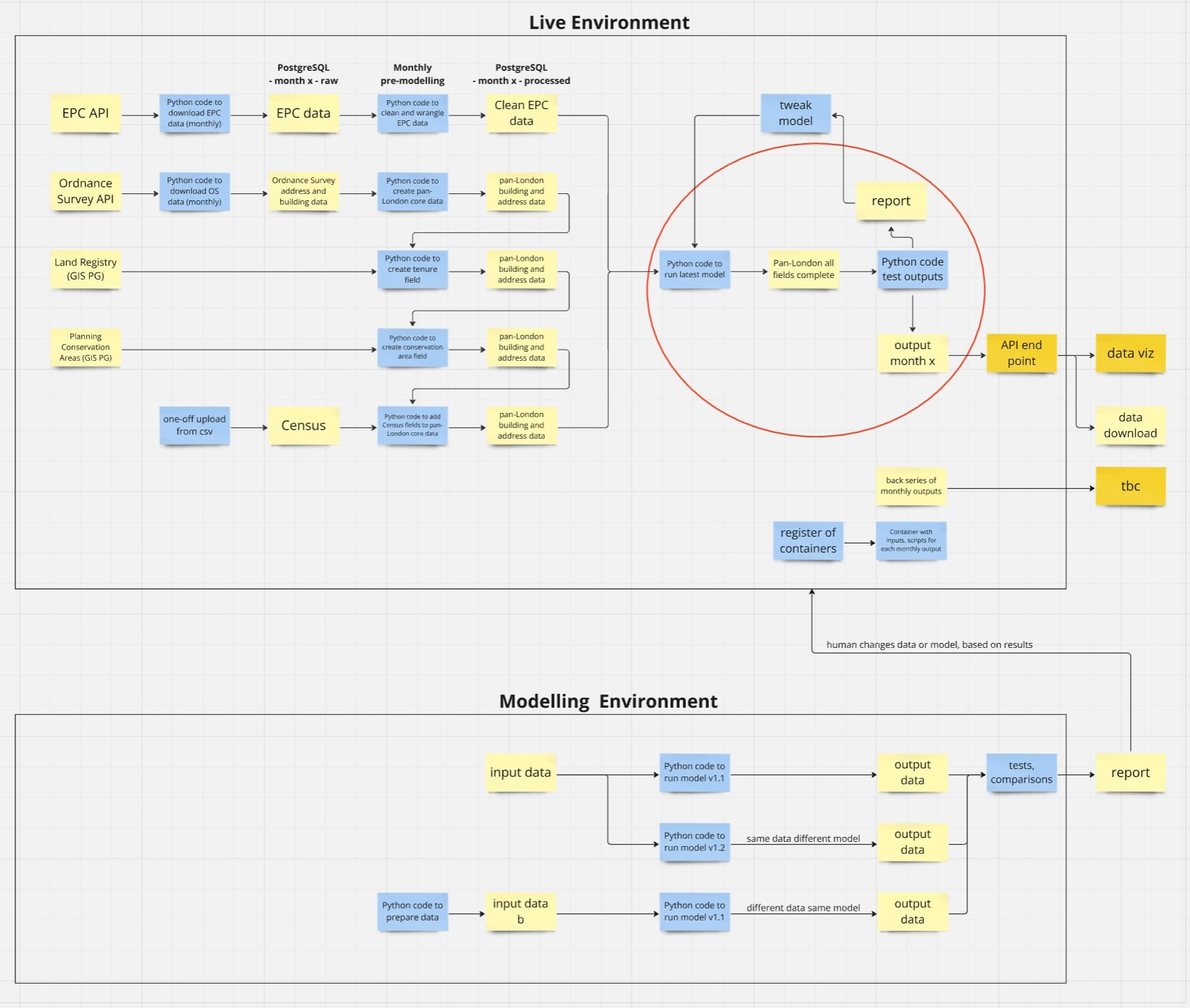{kind=link}
4.1.2 - Phase
Beta/Pilot
4.1.3 - Maintenance
One of the reasons for bringing the development in-house is to be able to continuously develop and improve the tool and make ad-hoc changes. The main types of changes will be:
- new input data sources becoming available that need integrating into the model.
- feedback from the users requiring changes to the output variables.
- improvement that can be made in the accuracy of the model.
- maintenance will focus on re-running the best available model with the most recent data and data quality assurance checks, planned to be monthly or quarterly.
4.1.4 - Models
The tool currently uses the LightGBM model - a type of decision tree boosting algorithm.
Tier 2 - Model Specification
4.2.1 - Model name
LightGBM
4.2.2 - Model version
3.1
4.2.3 - Model task
Predict missing data to produce a complete building stock dataset.
4.2.4 - Model input
See datasets listed below.
4.2.5 - Model output
The key output is a table with a record for all 3.8m residential properties and values for each of the 21 variables. Each values is flagged as to it’s source (for instance EPC, modelled, etc).
4.2.6 - Model architecture
LightGBM model - a type of decision tree boosting algorithm. Further resources can be found here: https://lightgbm.readthedocs.io/en/stable/Features.html
As the model uses sequential target prediction, categorical and numeric variables need to be predicted. An LGBM regressor is used to predict the numeric/continuous variables (e.g. total floor area) and an LGBM classifier is used to predict the categorical variables (e.g. roof type and finally the energy rating).
4.2.7 - Model performance
Accuracy of output is currently 87%, however we are working to improve this further.
4.2.8 - Datasets
- Energy Performance Certificates (EPC) - CARD
- Ordnance Survey building data (MasterMap and AddressBase Plus) - CARD
- Census 2021
- Land Registry (UK companies that own property in England and Wales) - CARD
- GLA retrofit programmes
- Colouring London
- SGN average energy demand data
- LBSM v1
4.2.9 - Dataset purposes
The input datasets are linked together based on the UPRN (unique property address) or the building’s location to create a data frame of all properties and all variables, with known values in place and gaps where prediction is needed. This data frame is then used for training the model, using a sample of properties.
Tier 2 - Data Specification
4.3.1 - Source data name
- Energy Performance of Buildings Data: England and Wales (EPC)
- Ordnance Survey MasterMap Topography (Building outlines)
- Ordnance Survey AddressBase Plus (Addresses within buildings)
- Census 2021 (Housing information for small areas)
- Land Registry National Polygon Service & UK companies that own property in England and Wales (Tenure)
- Land Registry Price Paid Data (Identify new builds)
- Colouring London (Building Age)
- GLA’s RE:NEW programme (Building Age)
- GLA’s London Boiler Cashback Scheme (main heating system)
- London Solar Opportunity Map (roof type)
4.3.2 - Data modality
Tabular
4.3.3 - Data description
- Energy Performance Certificates are issued for new buildings, when properties are sold or when rented properties are let. They consist of observations made by a surveyor about property type, insulation, heating type, etc - along with an overall rating (current & potential).
- The Ordnance Survey data is combined so that we can infer building type (semi-detached, terrace, blocks of flats, etc, ) - along with identifying nearest neighbours for each building
- Census data isn’t released at building level, but provides local constraints for modelled data (for instance % of properties that are owner-occupied)
- Land Registry data provides the type of organisation that owns the land for each property
- Colouring London is data about building age provided by volunteers, historical societies, architectural practices and researchers
- Misc. property-level data collected by past GLA programmes
4.3.4 - Data quantities
The cleaned EPC data consists of approximately 2m records.
The Ordnance Survey data consists of 3.8m records
The training sample varies across the variables (some being more complete than others). However of the data that is available for each variable an 80% training sample is used.
4.3.5 - Sensitive attributes
None
4.3.6 - Data completeness and representativeness
- Energy Performance Certificates cover 60% of properties, however, many records are incomplete.
- Ordnance Survey, Census and Land Registry provides 100% coverage - The list of OS addresses provides our definition of 100% and other variables are predicted against this list
4.3.7 - Source data URL
https://epc.opendatacommunities.org/ https://www.ons.gov.uk/datasets/TS054/editions/2021/versions/1 https://www.gov.uk/guidance/about-the-price-paid-data https://colouringbritain.org/data-extracts.html
4.3.8 - Data collection
No data directly collected for this model
4.3.9 - Data cleaning
Prior to modelling the data is extensively cleaned using data engineering techniques, combining very detailed categories into higher level ones and dealing with multiple surveys to the same property.
4.3.10 - Data sharing agreements
- Ordnance Survey data was used under the Public Sector Geospatial Agreement (PSGA)
- Land Registry data was purchased directly from Land Registry
4.3.11 - Data access and storage
The data will be stored in cloud databases and storage, managed by the GLA.
The input datasets and models will only be accessible by a small group of trained GLA data scientists and data engineers.
Because the modelled outputs contain Ordnance Survey data, sharing is governed by the PSGA. London Boroughs are PSGA members and so can access the outputs automatically. The outputs can also be shared using a ‘contractors licence’ with organisation working on behalf of the GLA Boroughs (for instance, retrofit installers)
Tier 2 - Risks, Mitigations and Impact Assessments
5.1 - Impact assessment
No impact assessments were required as the model doesn’t use personal data or data that through combining and modelling might create personally identifiable data.
- Ordnance Survey, planning areas and other building information does not constitute personal data
- Census data is already aggregated and anonymised
- Energy Performance Certificates (EPCs) - The Department for Levelling Up, Housing & Communities (DLUHC) has published a data privacy impact assessment (DPIA) https://www.gov.uk/government/publications/making-better-use-of-energy-performance-of-buildings-data-privacy-impact-assessment
5.2 - Risks and mitigations
The outputs from the model will be used to identify neighbourhoods or clusters of similar properties in terms of building type, age, tenure, heating type, etc. The individual properties within these ‘search areas’ will then need to be surveyed as part of the detailed design of any retrofit measures. This is needed because EPCs do not contain sufficient detail for this installation design and although modelled EPC values have high accuracy (80 - 90%) they are not 100% accurate.
There is a theoretical risk that a householder will be disbenefitted from an incorrectly modelled LBSM 2 value about their property. However, because the sifting is being done at a neighbourhood level, in practice this is a very small risk. The risk is much greater without modelling as the picture of London from existing EPCs is only partial and not fully representative of London’s housing stock.