Cost-benefit awareness tool
Published 7 November 2024

© Crown copyright 2024
This publication is licensed under the terms of the Open Government Licence v3.0 except where otherwise stated. To view this licence, visit nationalarchives.gov.uk/doc/open-government-licence/version/3 or write to the Information Policy Team, The National Archives, Kew, London TW9 4DU, or email: psi@nationalarchives.gov.uk.
Where we have identified any third party copyright information you will need to obtain permission from the copyright holders concerned.
This publication is available at https://www.gov.uk/government/publications/privacy-enhancing-technologies-cost-benefit-awareness-tool/cost-benefit-awareness-tool
Purpose of this tool
This toolkit is designed to support organisations considering adopting emerging privacy enhancing technologies (PETs). PETs can be adopted across different sectors and by organisations of different sizes. However, the potential of these technologies has not yet been fully realised, with adoption currently limited to a relatively small number of use cases.
This resource provides information about some of the costs and benefits associated with the adoption of these technologies. It is designed for use by individuals within organisations such as data officers, data architects, data scientists, as well as business unit owners assessing the opportunities that adopting these technologies may bring. It explores key areas that organisations looking to adopt PETs may wish to consider when assessing technical options or making a business case for a project. It does not attempt to quantify costs and benefits, as they are highly context and use case specific.
This resource has been created by the Responsible Technology Adoption Unit (RTA) in the UK government’s Department for Science Innovation and Technology (DSIT), in partnership with the Information Commissioners Office (ICO). It is intended to assist organisations to make well-informed decisions about the use of emerging PETs but is not a statement of formal government policy or regulatory guidance. This document is intended to offer suggestions as to how organisations can make use of emerging PETs. This document is not legal advice. Should you require legal advice, you should seek this from independent legal advisors.
Introduction
What are privacy enhancing technologies?
A privacy enhancing technology (PET) is a technical method that protects the privacy or confidentiality of sensitive information. This term covers a broad range of technologies including more traditional PETs and more novel, emerging PETs.
Traditional PETs are more established privacy technologies, such as encryption schemes, which are constituted by methods that secure information during transmission and when stored; de-identification techniques such as tokenisation, which replaces sensitive data with unique identifiers; and generalisation, which removes specific details to reduce data sensitivity.
This toolkit focuses on emerging PETs which are comparatively novel solutions to privacy challenges in data-driven systems. Whilst there is no fixed definition of emerging PETs, this toolkit primarily considers the following technologies:
-
homomorphic encryption (HE): a method of encryption that enables computation directly on encrypted data.
-
trusted execution environments (TEEs): a secure area within a processor that runs alongside the main operating system, isolated from the main processing environment. Also known as secure enclaves.
-
multi-party computation (MPC): cryptographic protocols that enable multiple parties to share or collaborate to process data without disclosing details of the information each party holds.
-
synthetic data: artificial data generated to preserve the patterns and statistical properties of an original dataset on which it is based.
-
differential privacy: a formal mathematical approach to ensuring data privacy, which works by adding noise to either input data, or to the output it produces.
-
federated analytics: processing data in a decentralised manner to produce analysis or carry out machine learning, often used alongside combinations of the technologies listed above.
Background to this toolkit
PETs can be utilised to support a wide and increasing range of use cases across many sectors (See our Repository of PETs use cases).
This toolkit is structured around a high-level use case: using privacy-preserving federated learning to enable the training of machine learning models without sharing data directly.
This use case focuses on a subset of federated analytics, known as federated learning, layered with other PETs to increase both input privacy (protecting raw data during the processing stage in training a machine learning model) and output privacy (protecting data that is shared or released after processing). The combination of federated learning with other PETs is often referred to as privacy-preserving federated learning (PPFL).
We use this PPFL use case to structure this guide, as it involves a range of relevant PETs, and provides a concrete basis to frame potential costs and benefits against a clear baseline. This type of use case was the focus of the UK-US PETs Prize Challenges in 2022-23, and in our work designing those challenges we identified PPFL use cases as having potential to improve data collaboration between organisations and across borders, without compromising on privacy. However, the analysis of the document remains relevant to other deployments of the same emerging PETs in related contexts.
Alongside this tool we have produced a checklist to support organisations considering utilising PETs to ensure they have considered the impacts outlined in this document.
Navigating this toolkit
Section 1 examines the costs and benefits of federation, i.e. training a model while the data remains distributed across different locations or organisations, which is integral to our PPFL use case.
The following sections (Sections 2 and 3) discuss the costs and benefits incurred by layering other PETs at different points in this solution. They consider the deployment of additional PETs to two ends: improving input privacy (Section 2) and improving output privacy (Section 3). These terms are explained below.
Different sections of this document may be more useful and relevant than others to certain readers depending on their intended use case.
- readers interested in federated analytics or federated learning (without additional input and output privacy techniques) should read this introduction and Section 1.
- readers interested in PPFL should read this document in its entirety.
- readers interested in approaches to improve input privacy (or any of homomorphic encryption, trusted execution environments, and multi-party computation) should read Section 2.
- readers interested in approaches to improve output privacy (or either of differential privacy or synthetic data) should read Section 3.
The remainder of this section introduces federated analytics, federated learning and PPFL, technologies which enable the use case assessed throughout this document. This section then introduces a baseline solution, that uses more traditional methods, to provide a point of comparison to our PPFL solution throughout the rest of the document.
Input and output privacy
Input privacy focuses on protecting raw data throughout the processing stage. Effective input privacy ensures that no party can access or infer sensitive inputs at any point. This protection may involve:
-
preventing unauthorised access: ensuring that all processing of data is conducted without any party being able to access or infer the original raw data. This involves a combination of access controls and protection against indirect inference attacks.
-
offensive security considerations: anticipating and countering potential offensive security techniques that adversaries could employ to gain unauthorised access to a system. This includes defending against attacks that leverage observable systemic changes such as timing or power usage.
-
proactive attack countermeasures: utilising robust defensive techniques and methodologies, including quality assurance cycles and rigorous red-teaming exercises (red-teaming, also used in the UK and US PETs Prize Challenge, 2022-2023, is a process in which participants known as ‘red teams’ deliberately simulate attacks that might occur in the real world to rigorously test the strength of solutions created by others), to proactively minimise attack vectors. These measures can help identify and mitigate potential vulnerabilities that could be exploited through the likes of side-channel attacks.
Input privacy may be improved by stacking a range of PETs and techniques across a federated solution. The sort of PETs and techniques encompassed by such approaches can be hardware and/or cryptographic based and are often viewed as synonymous concepts to security itself. For more information on input privacy see Section 2: Input Privacy Considerations.
Output privacy is concerned with improving the privacy of outputted data or models. Protecting processed data is important to prevent potential privacy breaches after data has been analysed or used to train models. Key considerations include:
-
implementing output-based techniques: techniques which add random noise to the training process of models, such as differential privacy can be particularly effective for ensuring that training data, or subsets thereof, cannot be extracted at a later stage. This approach can help to protect data even when a model is shared or deployed.
-
balancing privacy with model performance: techniques like differential privacy can affect a model’s performance, including accuracy. The trade-offs between privacy and performance should be carefully examined, considering factors such as the size of the model and the significance of accuracy relative to the specific research question.
Output privacy may be improved by effectively implementing a range of PETs and techniques across a federated solution. For more information on output privacy see Section 3: Output Privacy Considerations.
Federated analytics and learning
Federated analytics is a technique for performing data analysis or computations across decentralised data sources. It enables organisations to use data that cannot be directly shared. Local data from multiple sources is used to inform a global model or perform complex analysis, using federated approaches without sharing the actual data itself. After data is processed locally, the results of this processing are aggregated (either at a global node or between local nodes).
In this toolkit we define federated learning as a subset of federated analytics. Federated learning involves training a machine learning model on datasets distributed across multiple nodes. This approach uses model updates from many local models to improve a central or global model. Nodes transfer updated model parameters based on training conducted on locally held data, rather than the actual data itself. This allows for the training of a model without the centralised collection of data.
Example 1: Federated analytics for statistical analysis
A healthcare organisation looks to collaborate with universities and counterparts across countries to analyse trends in disease outbreaks. The organisation develops data pipelines to partners’ locally stored data. Through these pipelines, the organisation can send requests for data analysis.
The analysis is performed locally, without the healthcare organisation having access to the dataset. The output of this analysis is then returned to the organisation, which aggregates the results from all partners.
Example 2: Federated learning for training a model
A technology organisation wants to improve the accuracy of a voice recognition system without collecting their users’ voice data centrally. The organisation creates an initial model trained on a readily available data set, which is then shared to users’ devices. This model is updated locally based on a user’s voice data.
With user consent, the local models are uploaded to a central server periodically, without any of the users’ individual voice data ever leaving their device. The central model is continually iterated using the local models collected from repeated rounds of localised training on users’ devices. This updated central model is then shared to users’ devices and this training loop continues.
Privacy preserving federated learning (PPFL)
Layering additional PETs on top of a federated learning architecture is often referred to as privacy-preserving federated learning (PPFL). Use of additional PETs on top of federated learning can improve input and/or output privacy.
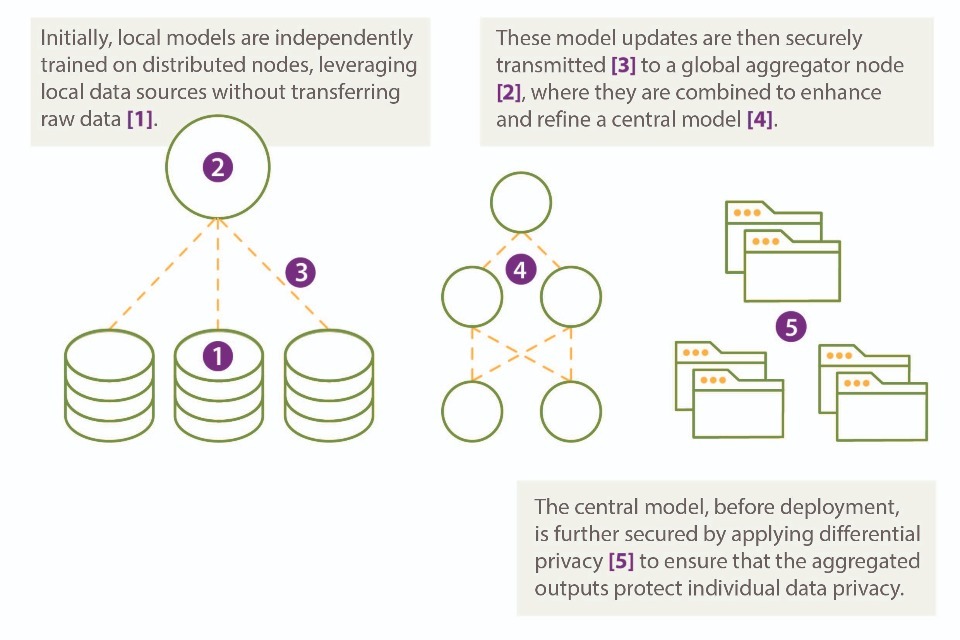
Figure 1: shows an example of a PPFL solution and illustrates a multi-step process where PETs are strategically implemented to enhance privacy across a federated network.
[1] Database structures at local nodes
[2] Central Global node (aggregator for federated learning)
The mechanisms behind many of these approaches and combinations will be discussed in more detail at a later stage. This comprehensive approach ensures that from data input to model deployment, every step provides a degree of privacy protection, safeguarding against unauthorised data exposure and enhancing trust in the federated learning process.
The accompanying explanations also serve as a reference point for technical options or considerations for how to deploy these technologies practically in a specific use case. This is intended to illustrate an indicative approach to how these technologies can be usefully deployed, not a definitive guide as to the only correct way of doing so, nor a specific endorsement of these techniques as better than other potential approaches.
[1] Database structures at local nodes
1.a) Trusted execution environment (TEE) and federated learning:
Implementation: TEEs can be used to create a secure local environment for each node participating in federated learning. This ensures that intermediate computations on local data are securely isolated within a server enclave. While federated learning inherently prevents other parties from accessing local raw training data by sharing only model weight updates, TEEs add an additional layer of security.
TEEs can be used to create a secure local environment that further protects the computations and model updates from potential tampering or unauthorised access, even within the local device. This can be particularly useful in scenarios where there is a heightened risk of local attacks or when additional hardware-based security is required.
Interaction: Local model training for federated learning can occur within TEEs. In such a process, only model updates (not raw data) are sent to the central/global node (node [2] connected to database structures). This provides an additional layer of security while benefiting from collective learning.
1.b) Homomorphic encryption (HE) and multi-party computation (MPC):
Implementation: HE enables computations to be performed directly on encrypted data, ensuring that sensitive data remains protected even during processing. This prevents any party from accessing the unencrypted data, thereby enhancing privacy.
MPC allows multiple parties to collaboratively compute a function over their inputs while keeping those inputs private from each other.
By leveraging TEEs, HE, or MPC, organisations can carry out secure computations without revealing sensitive data, providing an additional layer of privacy that complements the inherent protections of federated learning.
Interaction: HE ensures that data remains encrypted during transmission and computation, while MPC allows these encrypted results to be combined securely at the global node or between databases, enhancing both input and output privacy. This combination of techniques helps to protect against inference attacks, and is particularly applicable in scenarios requiring collaborative analytics, allowing for collective computations that are secure and private.
1.c) Synthetic data generation:
Implementation: Synthetic data generation involves creating artificial datasets that replicate the statistical properties of real datasets. This synthetic data can be used for initial model training and testing without exposing sensitive information, making it valuable for scenarios where data privacy is a specific concern due to the involvement of especially sensitive information. If the synthetic data is well-crafted and does not contain any identifiable information, it generally does not require additional privacy techniques. However, in cases where there is a concern that the synthetic data could be correlated with external data to infer sensitive information, techniques like differential privacy can be applied to add an extra layer of protection.
Interaction: Synthetic data can be utilised to safely conduct experiments, validate models, or train machine learning systems without risking the exposure of real, sensitive data. The interaction between the synthetic dataset and the machine learning models or analytical tools remains similar to that of real data, allowing for accurate testing and development.
In situations where sensitive information could be inferred, the use of differential privacy or other privacy-preserving techniques ensures that even if the synthetic data is accessed by unauthorised parties, the risk of re-identification remains minimal.
[2] Central Global node (aggregator for federated learning)
2.a) Federated learning with differential privacy:
Implementation: Implementing differential privacy techniques at the aggregator, to add noise to the aggregated model updates, enhances the privacy of the model by making it harder to trace back to individual contributions.
Interaction: Combining federated learning with differential privacy ensures that even if the aggregated model is exposed, there is a lower risk of the privacy of individual data sources being compromised.
2.b) Federated learning with synthetic data:
Implementation: Synthetic data can be used to initially baseline and validate a machine learning model during the development phase. This approach allows for early testing and adjustment of model architecture using data that mimics real datasets without exposing sensitive information. Once the model is confirmed to be functioning as intended, it should then be trained further with real data to ensure accuracy and effectiveness before being deployed to local nodes for federated learning.
Interaction: Federated learning can utilise synthetic data for calibration and testing under various conditions, ensuring robustness before deploying the model with real user data. During the interaction phase, the model can be tested and refined using synthetic data, which helps to establish a solid foundation whilst reducing privacy breaches. However, it is essential to note that the model should not be pushed to local nodes for final training if it has only been trained on synthetic data. Instead, the model should undergo additional training with real data to ensure it performs accurately in real-world scenarios before deployment across the federated network.
[3] Connections between nodes
Federated learning and HE:
Implementation: HE might be used to encrypt the model updates as they are transmitted between nodes. These updates, while originally derived from the data, are no longer the raw data itself but rather parameter updates that represent learned patterns. Encrypting these updates ensures that even as they are aggregated and processed, the underlying data patterns remain protected from potential inference attacks.
Interaction: During the interaction phase, model updates are securely transmitted between nodes using HE. These updates are no longer the raw data but encrypted representations of the model’s learned parameters. This encryption ensures that while the updates are aggregated to refine the global model, they remain secure and inaccessible, protecting the privacy of the underlying data.
[4] Federated learning network
Model consolidation: Implementation: This section represents the consolidated output of a federated learning process a fully trained model that integrates insights derived from all participating nodes.
Interaction: The model, now optimised and refined through aggregated updates, embodies the collective intelligence of the decentralised network while maintaining the privacy of the underlying data.
[5] End-user devices (Client-side)
TEE and synthetic data on client devices:
Implementation: TEEs can be employed on client devices to securely process data and use synthetic data to simulate user interactions without risking exposure of real data. Synthetic data could be generated from real data or anonymised versions of a dataset.
Interaction: TEEs ensure that even if a device is compromised, the processing of sensitive data (real or synthetic) remains secure.
Baseline for comparison
When assessing the costs and benefits of adopting PETs, it is useful to compare the costs and benefits to alternative methods.
In this PPFL example, a useful baseline for comparison is the training of an equivalent model on centrally collated data. The data is assumed to be collected by the organisation, originating from different entities and containing personal or sensitive information.
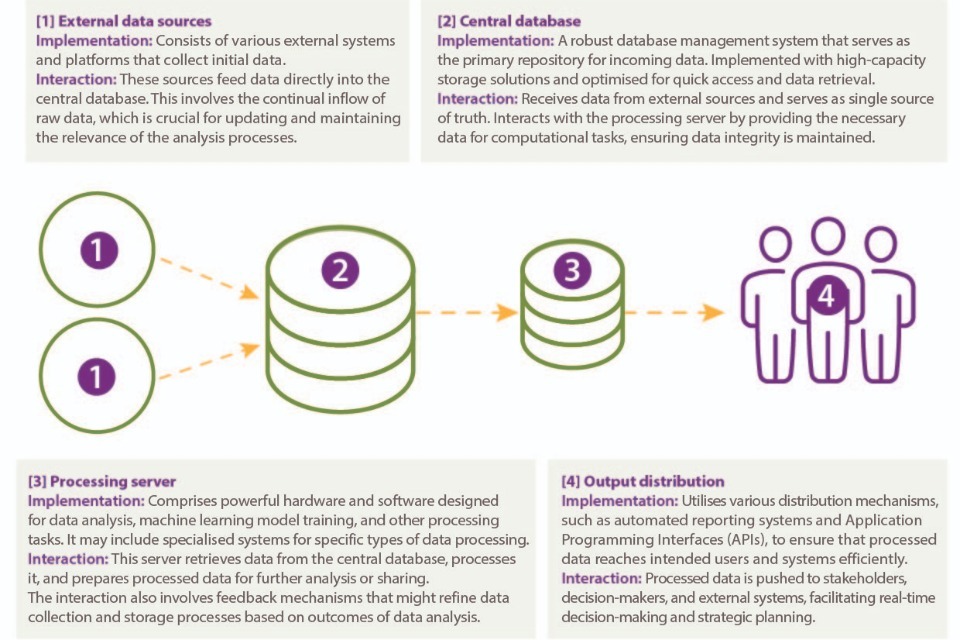
Figure 2: Example of baseline centralised data processing model
Section 1: costs and benefits of federated learning
This section examines the costs and benefits associated with implementing a federated approach to machine learning, without additional privacy protections. It explores technical, operational, legal and longer-term considerations, weighed against the comparative costs and benefits of implementing the baseline scenario described above.
Although some of the specifics refer to machine learning, the considerations outlined in this section are also applicable to federated analytics more broadly.
Later sections explore how additional PETs can be layered around this solution to enhance privacy.
Technical considerations
Data storage considerations
The baseline scenario requires organisations to set up and maintain a larger central database. Bringing together a large volume of data in one domain requires strong security protections; in many contexts this aggregation may raise the level of security required as the impact of data loss would be greater, and the threat model may be enhanced. If the data is gathered from multiple data-owning organisations, the central database may acquire the need to comply with multiple sets of security requirements.
Costs associated with this include the implementation of appropriate data governance and security mechanisms to protect and secure sensitive data, as well as ongoing operational costs associated with this. Such an aggregation often leads to a level of inflexibility, with any change in the central platform needing to be signed off by multiple data controllers or processors.
For federated learning, some of these costs may be lower. Most data will remain close to its source and will be processed locally, minimising the need for large central databases and reducing the risk from a single data breach or leak, and leaving control over individual data sets with the organisations that own them. It may also serve as a more efficient solution, in contrast with a centralised setup where copies of all the data from local sources will need to be made and processed centrally. Federated learning eliminates the need to duplicate data. However, other factors will need to be taken into consideration to assess this fully in an organisation’s specific context, for example, the readiness of existing data storage infrastructure.
| Baseline | PPFL |
| Implement once in one place. | Retain local control over data. Minimise risk from data breach by minimising aggregation. Avoid aggregation of security requirements from multiple organisations, and inflexibility due to complex multi-org governance regimes. |
Compute considerations in federated learning
In the baseline scenario, a substantial quantity of data will need to be processed centrally. This means that all the heavy lifting in terms of computation happens centrally, leading to high central computational costs.
By contrast, federated learning involves training models at local participant nodes before aggregating it centrally. This reduces the computational load on the central server and distributes the cost of data processing across the federated network. Therefore, the central computational costs are likely to be reduced significantly compared to the baseline scenario. In scenarios where the nodes are individual user devices, this may save costs centrally but could shift the burden and implicit cost to less capable devices, e.g. mobile phones. In multi-organisational setups, each participant bears part of the computational cost, which can lead to differing views on the cost-benefit ratio.
In addition to shifting the computational burden to less capable devices, federated learning can also introduce connectivity-related dependencies that may affect performance and reliability. Devices with intermittent or poor network connections may struggle to participate effectively in the federated learning process, potentially delaying model updates or causing inconsistencies in the global model. Furthermore, increased reliance on network connectivity can lead to higher latency and potential data synchronisation issues, which may degrade the overall efficiency of the learning process. These connectivity challenges must be carefully managed to ensure that all participating devices can contribute effectively without compromising the integrity of the federated mode. The above impacts will be more significant for more computational complex tasks. For example, the computational overhead of training a machine learning model is much greater than performing simpler analyses.
While federated learning likely reduces the computational overhead on central servers, it does not necessarily reduce the overall computational need. In fact, when summing the total compute across all nodes, federated learning can have higher total computational cost due to inefficiencies and the need to process on many nodes independently.
The performance and efficiency of federated learning depends heavily on the computational power of local nodes, which may vary. User devices, such as mobiles, have limited computational power and battery life compared to the likes of organisational servers, and local computational power can significantly impact performance.
By contrast, devices with more computational power can locally process more complex models without the same constraints at the expense of increased operational costs. Depending on the use case, it may be important to carefully assess and manage computational tasks and battery usage for federated learning on the likes of mobile devices. This consideration is more significant for more computationally intensive processes.
Layering in additional privacy-preserving techniques can significantly impact computational overhead. For more detailed information on the computational impacts of using additional PETs, see Section 2 and Section 3.
| Baseline | PPFL |
| Invest in advanced hardware in one location and use it efficiently. | Spread compute load among participants. |
Technical complexity
Data science and machine learning skills are in high demand in the market generally, often leading to higher salary costs and recruitment and retention challenges in either approach. However, there are some additional challenges in federated scenarios.
The additional complexity of running a federated learning process across several nodes requires blending understanding of data science and machine learning (ML), with increased expertise in how analytics code interacts with the infrastructure (compute, networking etc). In the centralised baseline scenario, most of this is typically abstracted away from the data scientist via a range of mature frameworks and software products. In a federated approach, the available frameworks are currently less mature, and fewer people have experience in deploying them in complex real-world scenarios. This has the potential to increase costs and risks in the short term; however, this is improving as federated approaches become more commonplace.
A federated approach can also add challenges for developers and data scientists. Often data science and machine learning require iterative exploration of the data, experimenting with different approaches and seeking to understand the outcomes. A federated approach, where the data is not directly available to the data scientist, can make this more challenging. This can also make troubleshooting issues more challenging.
Federated learning can also introduce potential complexities related to representation within datasets. For instance, when training models on data distributed across various sites, there may be significant differences in dataset characteristics, such as varying propositions of ethnic groups in medical datasets. These biases might not be visible to the coordinating server, necessitating additional efforts at the local level to ensure the data is suitable for federated training. This could involve extensive data preprocessing or detailed documentation to inform the unsighted coordinating party of potential biases, adding to the overall time and resource costs involved in the process.
Though this does represent an additional challenge for federated approaches, it is important to highlight that many of the same constraints might apply to a sensitive data set held centrally, where allowing a data scientist direct access to the raw data is either not possible at all, or only possible in highly constrained circumstances (e.g. a dedicated physical environment). Strategies such as using dummy data and automated validation processes can be effective approaches to counter the above challenges. These methods can help simulate potential issues and validate functionality in the absence of direct data access.
Privacy, data protection and legal considerations
Federated approaches are inherently more private than traditional centralised processes. The decentralised nature of federated learning prevents data from being shared, which minimises opportunities for data leakages or breaches. As the data is distributed across a federated network, the risk of the entire dataset being compromised is usually lowered. By contrast, in a centralised approach an entire dataset can be accessed if the sever is successfully attacked.
Despite the privacy and security benefits that can be derived from using federated learning compared to the baseline, use of federated learning on its own may, depending on the circumstances, not be sufficient to meet the requirements of the security principle of the UK GDPR.
For example, without additional PETs, federated learning may pose the risk of indirectly exposing data that is intended to be kept private that is used for local model training. This exposure can occur through model inversion, observing identified patterns (gradients), or other attacks like membership inference. This risk is present if an attacker can observe model changes over time, specific model updates, or manipulate the model. For more information on the risks of using federated learning without additional PETs, see the ICO guidance.
This risk of data breach exposes organisations to risk of legal action and from the ICO and/or data subjects, and associated fines; however, it should be noted that some of the risk levels should still be lower relative to centralised solutions.
While it is possible to use federated learning without additional PETs, organisations will likely find it more difficult to do so and demonstrate that adequate measures have been taken to protect personal data (compared to implementing federated learning with additional PETs. This may mean that organisations fail to fulfil the requirement for solutions to demonstrate data protection by design and default.
Use of federated learning without additional PETs may leave risks of re-identification of individuals from the model’s outputs open. Unauthorised re-identification of individuals could result in regulatory action from the ICO (this is discussed in more detail in Section 3). Deciding whether to use PETs for output privacy will depend on the nature and the purposes of the processing. Organisations will need to consider whether anonymous outputs are required, the size of the datasets, and the accuracy and utility required for the results of the analysis.
To mitigate many of these risks, organisations may wish to create a PPFL solution by layering multiple PETs. For more information on legal considerations associated with PETs that may be layered around a PPFL approach, see the sections linked below:
Section 2: Input privacy - legal considerations
Section 3: Output privacy and legal considerations
Although using federated learning without additional PETs will not protect data against all risks, federated learning could still provide benefits and improve security when compared to the baseline solution. In the event of an infringement, when considering whether to impose a penalty, the ICO will consider the technical and organisational measures in place in respect to data protection by design. Using federated learning may help to demonstrate proactive measures to reduce harm which may influence potential penalties favourably.
Data protection impact assessments (DPIA)
Use of privacy-preserving techniques may streamline the DPIA process, therefore potentially reducing legal costs. For example, by minimising the amount of personal data processed, federated learning solutions should inherently mitigate some privacy risks that would otherwise need to be accounted for.
Designing federated learning systems with data protection by design and default is likely to result in lowering inherent privacy risks. This could lead to the reduction of legal overhead involved in these assessments. For example, auditing the system could be less costly as compliance considerations would be ‘baked into’ the system design.
Distributing legal costs
In scenarios where multiple organisations participate in a federated learning project, shared legal resources or joint legal teams may help to distribute legal costs (if it is appropriate to do so in the circumstances) among the participating parties. However, it should also be noted that the use of unfamiliar emerging or novel technologies like federated learning can lead to protracted discussions between legal teams, as it may be challenging to reach a consensus on what constitutes sufficient security and privacy safeguards. To mitigate these challenges, establishing clear, standardised guidelines and best practices at the outset of the project can help streamline these discussions and reduce the time and cost involved in reaching agreements.
Federated learning reduces the risk of large-scale data breaches by keeping the data localised on devices rather than centralising it. Decentralised data handling minimises the attack surface and limits the impact of potential data breaches to individual nodes rather than the entire dataset.
The privacy-preserving nature of federated learning, avoiding the transferring of raw data, aligns with security best practices. This alignment can lead to a perception of reduced risk among insurers, potentially lowering premiums. However, this potential benefit is more likely to be realised if there are established, repeatable guidelines and standards for implementing federated learning securely. Without such standards, the variability in implementation could lead to inconsistent security outcomes, making insurers cautious.
Longer term considerations
Some of the benefits of the use of federated learning may only be fully realised in the longer term. Organisations should consider costs and benefits across the whole life cycle of a product/system, and this should include considering the wider opportunities that adopting federated learning could lead to in the future.
Longer term benefits of using federated learning include improving long-term efficiency for adding new data sources into model training, enabling the use of previously inaccessible data assets, wider network effects as more successful federated analytics solutions are deployed (all explored in further detail below).
Integrating new data sources
| Baseline | PPFL |
| Adding new data sources may result in a bespoke or semi-bespoke approach in each instance. | Standardises the approach to integrating new data sources, simplifying this process. |
Federated learning can improve long-term system efficiency as it establishes - through system design - a method and structure for integrating insights from different data providers.
In the long term, federated learning could simplify the process of integrating new data sources, thereby continuously enhancing the central model. While federated learning inherently facilitates the addition of data sources from diverse locations without centralising data, it is important to acknowledge that a well-designed centralised system could also be structured to accommodate future data integration effectively.
The key difference lies in the approach: federated learning naturally supports incremental data integration with minimal disruption, whereas centralised systems require careful foresight and design to achieve similar flexibility.
Getting value from data assets
| Baseline | PPFL |
| Some data assets are unmonetisable due to privacy/commercial/IP concerns. | Value can be derived from previously inaccessible data sources through privacy preserving approaches. |
Generally, federated approaches offer wider opportunities to benefit from the value of protected and sensitive data. Data owners might be able to unlock value from data assets that would not have been previously accessible, the value of the data to the data owner is protected by enabling use of the data without full access to it. Depending on the context, this might correspond to direct monetary value for the data, or broader social or economic benefits.
PPFL offers additional security which allows for greater control and management over the full data, which can enhance input and output privacy. Only information about model updates is shared which ensures the value of the actual data is preserved and can be utilised for further opportunities. In contrast, in the case of federated learning, the lack of additional layers of PETs for security limits the extent to which the value of the data can be protected.
Network effects
| Baseline | PPFL |
| Limited network effects due to centralised data and processes. | More opportunities to benefit from federated learning as it becomes a more widely adopted approach. |
Adopters of federated learning may see benefits compound over time due to network effects from wider use and adoption of federated approaches. While federated learning is relatively nascent, over time, the deployment of - and collaboration through - more successful federated analytics-based solutions could encourage greater uptake of the approach.
Wider adoption of federated learning will create further opportunities for use of federated approaches across organisations and sectors, which will result in further opportunities for collaboration and to unlock greater value from data.
Section 2: input privacy considerations
Introduction
Whilst federated approaches offer improvements in privacy compared to our baseline scenario, organisations may wish to layer in additional PETs to ensure that no processing party can access or infer sensitive inputs at any point.
Greater levels of input privacy can be achieved by stacking additional PETs such as trusted execution environment (TEE), homomorphic encryption (HE) or secure multiparty computation (SMPC) into a federated solution. See Figure 1 for examples on where these PETs fit in a PPFL architecture. These PETs can also be used for a wide range of other use cases, and organisations looking to deploy these technologies will encounter similar costs and benefits.
This section expands on the different types of PETs that can improve input privacy in our PPFL use case, the costs and benefits associated of these approaches and other use cases these PETs can enable.
Enabling technologies
Homomorphic encryption
Homomorphic encryption (HE) enables computation directly on encrypted data. Traditional encryption methods enable data to be encrypted whilst in transit or at rest but require data to be decrypted to be processed. HE enables encryption of data at rest, in transit, and in process. At no point are the processing parties able to access the unencrypted data, or to decrypt the encrypted data.
There are 3 forms of HE, each of which permit different types of operations:
-
partial homomorphic encryption (PHE): permits only a single type of operation (e.g. addition) on encrypted data.
-
somewhat homomorphic encryption (SHE): permits some combinations of operations (e.g. some additions and multiplications) on encrypted data.
-
fully homomorphic encryption (FHE): permits arbitrary operations on encryption data.
Unless stated otherwise, this resource uses HE to describe all forms of homomorphic encryption.
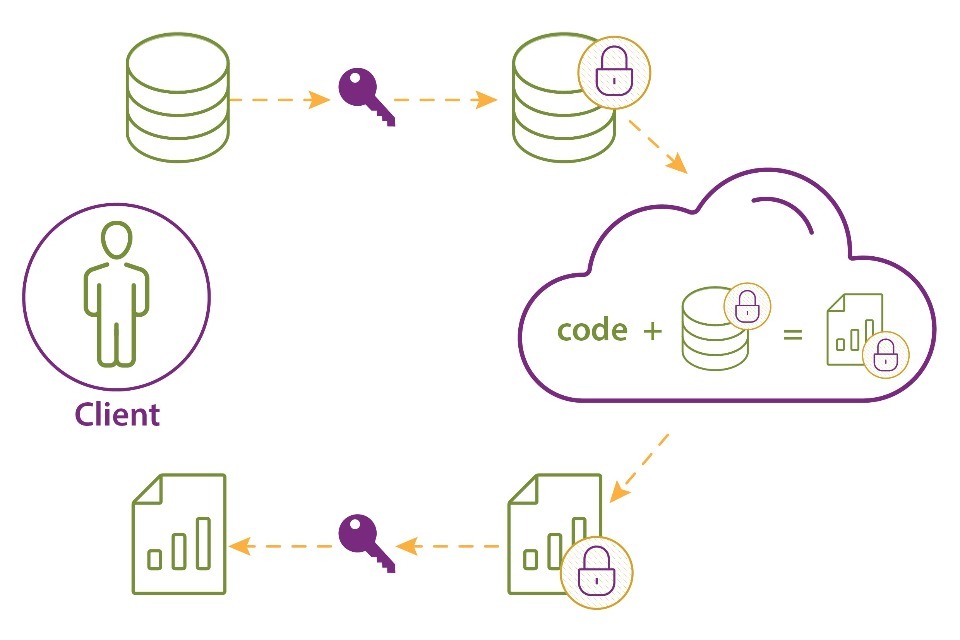
Figure 3: Homomorphic encryption
Example
A technology company running a password manager wants to monitor whether their users’ passwords have been compromised and leaked online. The organisation collects homomorphically encrypted versions of their users’ passwords and compares these passwords to lists of leaked passwords. The organisation can run these comparisons without being able to decrypt the users’ passwords. The organisation can then alert users if their passwords have been compromised, without ever actually having access to the users’ credentials.
Trusted execution environments
A trusted execution environment (TEE) is a secure area within a processor that runs alongside the main operating system, isolated from the main processing environment. It provides additional safeguards that code and data loaded inside the TEE are protected with respect to confidentiality and integrity. TEEs provide execution spaces which ensure that sensitive data and code are stored, processed, and protected in a secure environment. In practice, this means that even if the main processor or operating system is compromised the TEE remains secure.
This isolation prevents unauthorised access through a series of hardware-enforced controls. Additionally, the secure design of TEEs helps safeguard the broader processor system by containing any potentially malicious code or data breaches within the TEE itself. This containment ensures that threats do not spread to other parts of the system, thereby enhancing the overall security architecture and reducing the risk of widespread system vulnerabilities.
While TEEs provide strong security guarantees by isolating and containing potential threats, their effectiveness is also dependent on the trustworthiness of the TEE provider. For instance, the integrity of the TEE’s security features hinges on the provider’s ability to implement and maintain these controls while addressing any vulnerabilities. It is important to acknowledge that if the TEE provider is compromised or if the TEE has undiscovered vulnerabilities, the security assurances offered by the TEE could be undermined. Some TEE providers aim to mitigate these risks and enhance transparency and trust in TEEs by leveraging open-source code and independent verification processes, though these solutions are relatively nascent and are not discussed in further detail here.
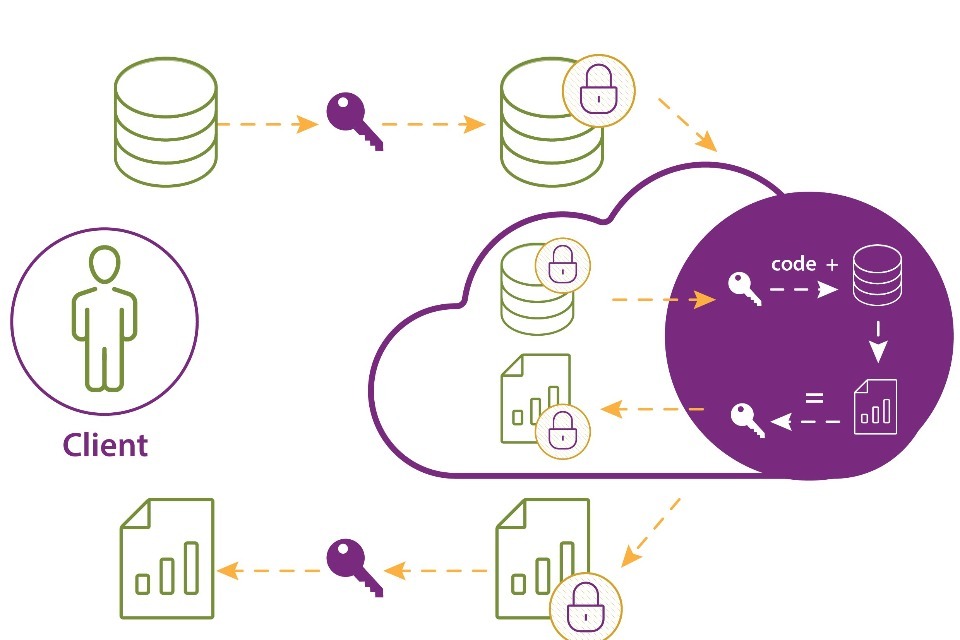
Figure 4: Trusted execution environments
Example
An organisation that develops a mobile messaging application wants to match users with contacts on their mobile who are also using the platform. The organisation does this by comparing a user’s contacts to their wider database of users. The organisation does not wish to access the user’s contact data directly. The user’s contacts are encrypted and uploaded to a TEE inside the company’s servers. Inside of this TEE, the user’s data is decrypted and compared against the company’s database of users. Information regarding matches between the user’s contacts and the company’s user base is then returned to the user. As the user’s contacts are only decrypted within the TEE, the company never has visibility of them, nor do they receive a copy of the unencrypted data.
Secure multiparty computation
A secure multiparty computation (SMPC) protocol allows multiple parties to collaborate on data whilst keeping inputs secret from others. Typically, this is done by fragmenting data over multiple networked nodes. Each node hosts an “unintelligible shard”, which is a portion of data that, in isolation, cannot be used to infer information about the original data. Functions are locally completed on the shards and the outcomes are then aggregated to produce a result.
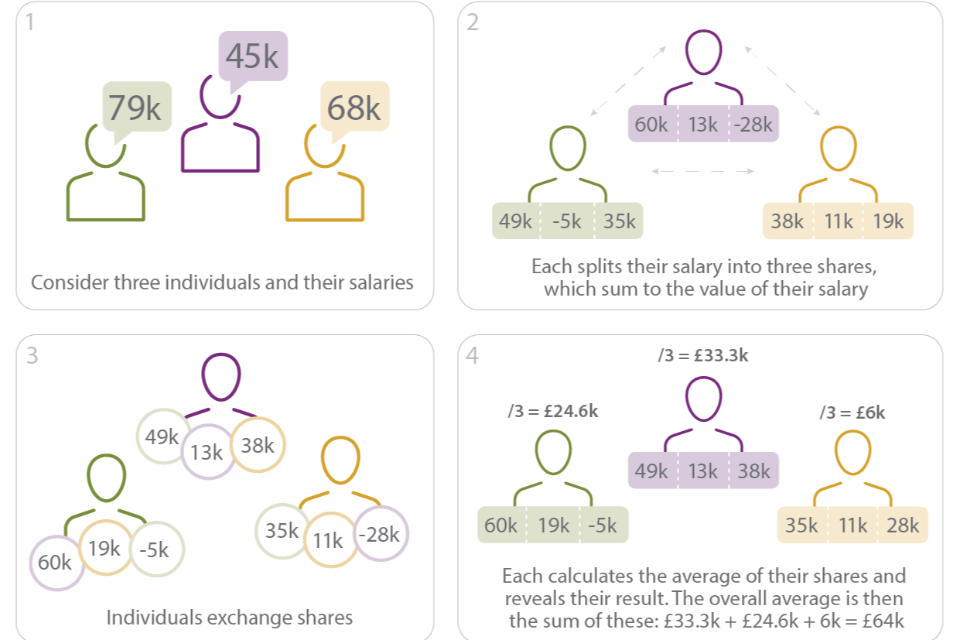
Figure 5: Very simple example of a secure multiparty computation implementation
Example
A group of employees want to understand average salaries without revealing their own salaries. SMPC uses basic mathematical properties of addition which split the computation between parties whilst keeping their actual salaries confidential. Once the results of local computations are recombined, the correct result can be obtained.
Case studies
-
BWWC (July 2021) Product - SMPC
-
Eurostat (June 2023) Proof of concept - TEE
-
Microsoft (July 2021) Digital product - TEE
-
Indonesia Ministry of Tourism (June 2023) Digital product - TEE
-
Secretarium/Danie (Finance) (June 2023) Product - TEE
-
Enviel (July 2021) Proof of concept - HE
Costs and benefits of deploying additional PETs for improved input privacy
Technical considerations
Use of SMPC, TEEs or HE can result in higher levels of privacy for federated solutions, but at the expense of data processor visibility. This lack of visibility can create issues in testing and troubleshooting when running code on the data. In TEE and HE solutions, data processors have no visibility of the data, ensuring confidentiality. SMPC involves the sharding of data, distributing unintelligible segments among various parties, ensuring that no single shard reveals any information about the original data. While there are options to mitigate testing difficulties, they may create additional costs.
PHE and SHE also create a privacy-utility trade off, as additional levels of privacy can limit the type and number of operations that can be performed on data. This is because, whilst these systems are typically more performant than FHE, they support only a limited number of predetermined operations. Organisations will have to assess the specific needs/requirements of their use case to choose the most suitable approach. FHE and TEEs do not face this same privacy-utility trade off. Whilst SMPC also does not have the same privacy-utility trade off, protocols must be set up in such a way that no shards of data contain a proportion of the dataset that would allow for inference of the original data.
By contrast, the traditional baseline example carries a lower technical cost than TEE, HE or SMPC as all data is directly available and visible. In a PPFL solution data access is also lower than the baseline example, however the deployment of these additional PETs adds an additional layer of technical complexity in exchange for increased data privacy.
Privacy preserving infrastructure in input privacy approaches
| Baseline | PETs |
| High level of utility due to data being decrypted and fully visible to all users. Data is visible to all parties and unprotected after decryption. |
HE solutions enable a greater degree of privacy than the baseline example because no external parties can view decrypted data at rest or in transit. TEE and SMPC solutions enable a greater degree of privacy than the baseline example but rely on a greater level of trust between parties than HE. |
Both HE and TEEs offer ways to enhanced privacy to pipelines, once data is shared to a network. Using HE, data remains encrypted whilst outside of the control of the data controller. A data processor can never access, or decrypt, the underlying data. With TEEs, data is only decrypted inside of the TEE, which is a distinct processing environment inaccessible to the data processor. Data is encrypted before it is moved out of the TEE and can only be decrypted again by the data controller.
TEEs rely on a greater level of trust between parties than HE, as there must be trust that environments have been correctly set up. TEEs also carry some security risks, such as via side channel attacks, where information about the computation within the TEEs is inferred from signals produced by the computing system. As TEEs are hardware-enabled, they can be challenging to patch if a vulnerability is discovered (see below - Testing and Troubleshooting).
SMPC has a unique set of privacy requirements relating to the trust that can be placed in parties at local nodes. Dishonest or colluding parties could leak information or disrupt SMPC protocols. Organisations may therefore wish to ensure additional resiliency against these attack vectors when designing protocols.
In comparison to federated learning without the use of SMPC, TEEs or HE, these solutions are considerably more secure. Unencrypted or ‘intelligible’ federated pipelines are vulnerable to a range of attacks including man in the middle attacks, which can be used to steal data from local nodes.
Compute considerations in input privacy approaches
| Baseline | PETs |
| The baseline example has variable latency and compute costs dependent on the scale of the data being processed. |
HE solutions have a higher level of latency compared to other technologies because of processing occurs directly on encrypted data. This may also result in higher compute overheads. TEE has lower latency compared to HE since data is processed without encryption. SMPC resulting in higher computational overheads than the baseline, however these are trivial in comparison to federated learning. |
SMPC results in a higher computational overhead compared to the baseline central dataset approach as more complex protocols are required for internode communication. However, if your organisation is deploying SMPC as part of a federated solution these overheads are likely to be trivial. Federated systems typically handle significant transmission of model updates and computation loads distributed across nodes, making the additional burden from SMPC less significant.
Both PHE and SHE offer a limited number of operations compared to SMPC, FHE and the baseline, thus constraining the type of processing activity that can be undertaken. Limitations to operations in PHE and SHE might, for example, prevent federated learning from being performed. Therefore, the nature of operations required by a system must be known before selecting a PHE or SHE schema.
FHE allows for arbitrary operations and does not have the same limitations in functionality as PHE and SHE. Organisations using FHE will be able to change the operations they are performing. However, FHE carries significant computational overheads, making data processing expensive, and affecting latency. Many complex operations are simply impractical. This is an active area of research where improvements are likely to occur in the future, and computational overheads are likely to reduce.
By contrast, data within a TEE, as with the baseline example, can be processed without encryption, making it more computationally efficient, thus cheaper and faster than HE. These savings may be significant when processing large quantities of data. Both TEEs and the baseline solution allow for arbitrary operations to be performed.
Testing and troubleshooting considerations
| Baseline | PETs |
| The baseline uses traditional approaches to testing and patching. | In HE and TEE solutions data is not visible to the data processor testing and troubleshooting may be more difficult and require mitigations at additional cost. Some data is visible to the data processor in SMPC. TEEs are hardware enabled which may necessitate additional mitigations and resources for testing processes and iterative bug fixes. |
Testing considerations
In both TEEs and HE, data is not visible to the data processor. This can create issues in identifying and solving issues when they arise. By contrast, in our baseline solution data remains visible to the data processor. To mitigate potential errors from arising, organisations using TEEs and HE may create additional verification pathways, dummy data for testing, and clear data schemas, at additional cost, to ensure that processes run as expected with HE and TEE solutions.
Both our baseline approach and TEE-based solutions can involve processing real data in environments that are not fully isolated or secure. This may lead to accidental data retention of sensitive data in log files, memory dumps, or intermediate computational results, which poses significant security and compliance risks.
Whilst SMPC reduces visibility into overall data by sharding it, this characteristic can complicate testing and debugging compared to environments like TEEs and HE. In the TEEs and HE, although data remains encrypted or isolated, the complete dataset is still intact and can be manipulated or checked in its entirety within the secure or encrypted environment.
This complete view facilitates easier identification and resolution of bugs of integration issues. In contrast, with SMPC, the fragmented nature of data handling means that errors related to data integration or interpretation across different parties can be challenging to detect and rectify. Debugging in SMPC often requires sophisticated simulation and synthetic data approaches to effectively mimic the distributed computation process and ensure that the collective operations yield the correct results.
Patching considerations
Whilst SMPC, TEEs and HE are typically more secure than the baseline example, they are not infallible, and vulnerabilities in systems that make use of them can still arise.
As TEEs are hardware-based, patching for vulnerabilities can be more challenging than patching vulnerabilities in software-based solutions. When issues in TEEs arise, physical hardware may need to be replaced to mitigate threats or issues, resulting in replacement costs and as well as costs associated with downtime required to fix an issue.
Fixing issues or vulnerabilities in an SMPC, HE, in a standard federated learning scenario, or in our baseline scenario will not face the same issues, as they are software-based.
Legal considerations for input privacy approaches
| Baseline | PETS |
| Complies with standard data protection laws but may require additional safeguards to prevent unintentional data leakage. |
HE enhances compliance with data protection laws by ensuring that data remains encrypted during processing, reducing the risk of data breaches. TEE provides strong protection while data is processed but requires robust procedures to ensure the secure setup and maintenance of environments. SMPC can provide adherence to data privacy principles if the proper mitigations against actions by colluding parties are taken. |
Organisations designing systems that use HE or TEEs to process personal or sensitive data must engage legal and regulatory teams to ensure compliance with data protection laws and sector-specific regulations. The use of either TEEs and HE can help organisations to comply with data protection legislation, reduce compliance costs and minimise the burden of legal duties on organisations. These technologies can also provide easier and more cost-effective routes to compliance than our baseline solution.
SMPC ensures that only necessary information is shared without compromising data utility or accuracy. Use of SMPC can demonstrate compliance with the security principle by keeping other parties’ inputs private, preventing attackers from easily altering the protocol output. Furthermore, use of SMPC can aid with adherence to the data minimisation principle, as parties learn only their output, avoiding unnecessary information exposure. Additionally, SMPC helps mitigate personal data breach risks by processing shared information separately, even within the same organisation.
Data disclosure
Use of either TEEs or HE protects data that is being processed from disclosure to the processing party. By contrast, in the baseline scenario this data remains open and visible to the data processor.
TEEs process data in an isolated environment. This ensures that data being processed is protected from disclosure, and provides a level of assurance of data integrity, data confidentiality, and code integrity.
HE protects data from being disclosed as it ensures that only parties with the decryption key can access the information. It can provide a level of guarantee to an organisation when outsourcing a computation in an untrusted setting. The processing party never learns about the “original” unencrypted data, the computation, or result of the computation.
SMPC also can meet the requirements of protecting data from disclosure, providing that risks around collusion between dishonest parties are sufficiently mitigated.
This protection from disclosure can help organisations comply with both the security principle and the requirements of data protection by design under UK GDPR, in ways that our baseline scenario do not.
Data breaches
Use of TEEs, HE and SMPC can also help mitigate the risks of data breaches, and associated penalties and reputational damage, compared to our baseline scenario.
TEEs reduce the risk of data breaches by providing a secure environment for data processing and strong supply chain security. This is because TEE implementations embed devices with unique identities via roots of trust (i.e. a source that can always be trusted within a cryptographic system).
HE also protects against risks of data breaches. As data is encrypted whilst at rest, in transit, and in process any data leaked should remain unintelligible to an attacker.
Similarly, SMPC also reduces the risk of data breaches as fragmented data that is distributed over multiple networked nodes cannot, in isolation, be used to reveal or access the original data. In all cases, the additional protections from data breaches provided by TEEs, SMPC and HE can potentially lower legal liabilities and costs faced by organisations. None of these additional protections are provided in our baseline scenario.
Data governance
Correct use of TEEs can assist organisations with data governance in practice, which can help to reduce costs associated with auditing and other compliance requirements. Compared to the baseline scenario and to HE and SMPC, TEEs can introduce efficiencies by streamlining and automating aspects of governance and transparency.
For example, TEEs can be configured to provide reliable and tamper-proof logs of data processing activities for auditing. This logging can enable an organisation to trace each operation within a TEE back to an authenticated entity (e.g. user, process, or system), and therefore help an organisation comply with the accountability principle in the UK GDPR.
Section 3: output privacy considerations
Introduction
This section will consider approaches for ensuring data remains secure once it has been processed (output privacy).
Organisations can employ a range of traditional methods to achieve this, such as anonymising data before publishing it or sharing it for further processing. For example, anonymising datasets before sending them to untrusted nodes or preventing access to data during transit to mitigate immediate risks.
In a PPFL use case, output privacy can be improved by layering additional PETs like synthetic data or differential privacy (DP) into the federated solution. See Figure 1 for examples of where these PETs can fit in a PPFL architecture. This section will explore the costs and benefits associated with these approaches in more detail. These PETs are applicable to a wide range of other use cases, and organisations considering these methods will encounter similar costs and benefits, particularly when these methods are viewed as alternatives to traditional anonymisation or pseudonymisation techniques.
Enabling approaches
Differential privacy
Differential privacy (DP) is a formal mathematical framework designed to ensure data privacy. It achieves this by adding noise to data, which involves the insertion of random changes that introduce distortions, either to the input data or to the outputs it generates. By injecting random noise into a dataset, DP increases the difficulty of determining whether data associated with a specific individual is present in the dataset.
In DP, noise is added using randomised mechanics that reduce a network’s ability to memorise explicit training samples. The more noise added, the more inaccurate the final dataset is likely to be, leading to a privacy-utility trade-off. This trade-off is quantified by the concept of Ɛ-differential privacy, where the Ɛ parameter represents the worst-case amount of information inferable from the result of a dataset. The privacy budget, defined by Ɛ, sets the threshold of the maximum amount of noise to be added to a dataset. This budget varies based on context and application. It is worth noting that there is no standardised way of determining how Ɛ should be calculated.
Applications of DP can be widely categorised into interactive and non-interactive approaches. Each method has implications for data utility and the privacy budget at the implementors disposal. Understanding these distinctions is important for determining the most appropriate method for organisational needs and specific use cases.
Interactive DP is implemented through mechanisms that allow users to query a database and receive noisy answers. This approach typically involves a trusted curator or algorithm adding noise to queries in real-time. The system tracks the privacy budget and ensures that the total noise added to queries does not exceed this budget.
Non-interactive DP involves sanitising datasets or generating and releasing synthetic datasets that preserve the statistical properties of the original data while ensuring privacy. In this approach, the data publisher creates a differentially private dataset pre-processed with noise, ensuring that subsequent interactions with the data do not involve the original dataset.
Non-interactive DP can also enhance input privacy. For instance, an organisation might generate a sanitised dataset using non-interactive DP, which is then used in an interactive DP system. This combination ensures further queries to the database are doubly secured: initially through the sanitised data and subsequently via real-time noise adjustments based on each query.
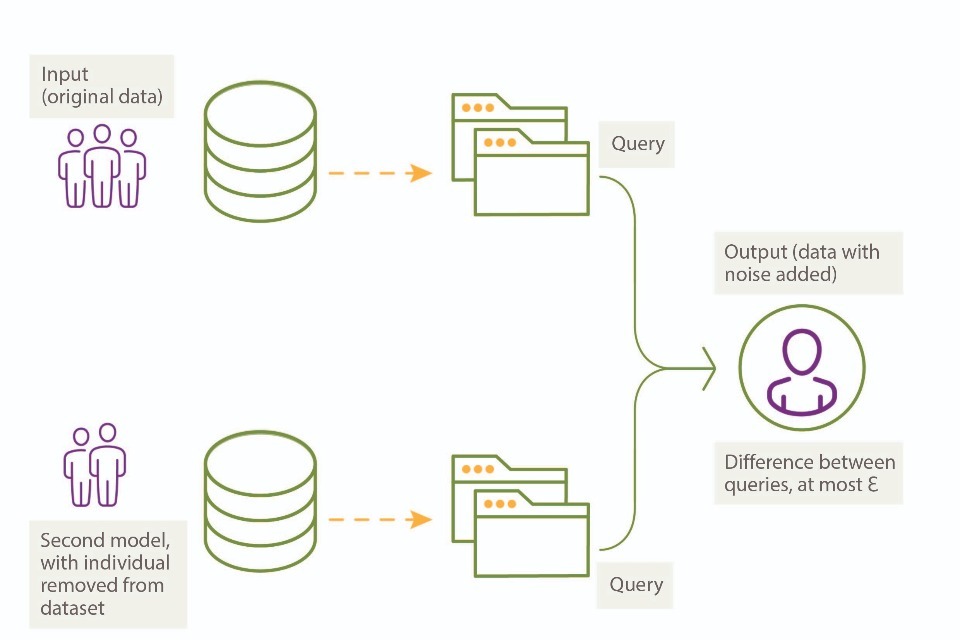
Figure 6: Differential privacy
Example
A social media company wants to release data around about users’ on-platform interest in television shows to allow researchers to assess trends. To ensure users cannot be identified, noise is injected into the dataset. In this case the television shows are categorised into genres, and the noise added changes the actual shows into shows of the same genre. This ensures users’ actual preferences in television shows are differentially private while maintaining the overarching trends in the data.
Synthetic data
Synthetic data can also be used to enhance output privacy to protect sensitive information at the point when it is shared/released if it uses differential privacy. Synthetic data is artificial information that is generated to preserve the patterns and statistical properties of an original dataset on which it is based. As this artificial data will not be identical in detail to the original data, it offers a way to protect individuals’ data privacy, enable further analysis to be carried out on the data, and for the trends and characteristics in the data to be more widely accessible.
Different types of synthetic data include:
-
partially synthetic data - contains some real data but removes sensitive information.
-
fully synthetic data - includes no original data. In this case, an entirely new dataset is generated to mimic properties of the original data.
-
hybrid synthetic data - this approach includes both real and fully synthetic data.
-
Synthetic data may be static (generated once and fixed) or dynamic (generated and updated multiple times).
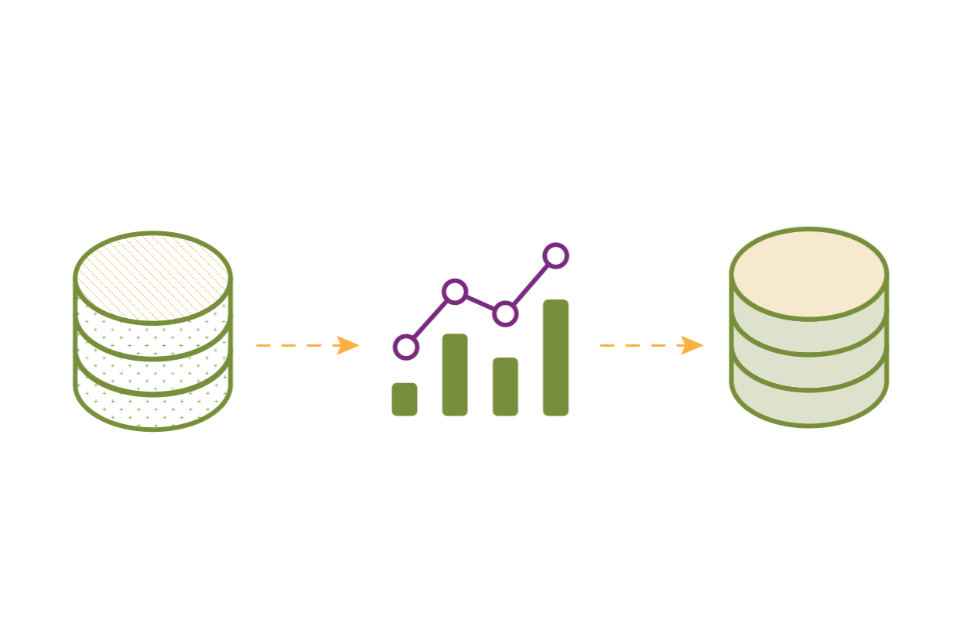
Figure 7: Synthetic data generation example
Example
A policy research organisation wants to publish data on outcomes from a study to enable further research. The dataset includes sensitive information, but the organisation wishes to share it in as much detail as possible to allow for further analysis. They upload the original data to a synthetic data generator. The generator identifies statistical patterns in the dataset which are replicated to create an entirely new synthetic dataset containing none of the original data.
Case studies
-
Statice - predictive analytics for insurance (June 2023) Synthetic Data
-
Replica Analytics - healthcare data for research (June 2023) Synthetic Data
Costs and benefits of layering additional PETs into PPFL for improved output privacy
Technical considerations
Use of DP or synthetic data can enhance output privacy in the context of a PPFL use case. Both approaches carry additional computational costs. Ensuring that data is sufficiently private to prevent it being recoverable is an important consideration when using either synthetic data or DP. Both approaches involve a privacy-utility trade-off, where an increase of one feature comes at the expense of the other. Organisations will need to consider the specific context of their use case, to establish how to balance this trade-off.
Privacy preserving infrastructure in output privacy approaches
| Baseline | PETs |
| Potentially higher utility and lower levels of privacy. For legal and governance reasons some sensitive data may not be shared. |
The use of synthetic data and DP techniques can reduce the utility of the data as privacy is injected due to the changing distribution of trends in datasets. Organisations seeking to deploy these technologies should consider trade-offs between the appropriate level of privacy when sharing data and the required level of functionality to effectively use the solutions. Synthetic data and DP enable sensitive data to be shared on acceptable form that would not previously be able to because of privacy concerns. |
Both DP and synthetic data have a higher level of privacy than anonymising data through more traditional methods, however this comes at the cost of utility.
In DP, should the privacy budget be too high the data can lose its utility, whereas if it is too low original data can be recovered with a greater degree of certainty Injecting greater amounts of noise into a dataset may cause trends in the data to be lost, or inaccuracies to be introduced. These effects are more pronounced for smaller sub-populations represented in the data. This is highly context dependent, and with no existing standards on privacy budgets, organisations will need to decide on how much utility they are willing to trade off make the dataset sufficiently differentially private. In some contexts/use cases, organisations will also need to consider how to communicate this to users.
Similarly in synthetic data, the creation of datasets from trends in real data is not guaranteed to be reflective of the original because of factors including the scale of the original dataset compared to the synthetic dataset or the type of synthetic data deployed (full, partial, etc.). For example, if a dataset has few categories of a particular characteristics these patterns may be lost new data is generated or scaled up due to the generation tool amplifying existing trends and biases in the data. This can result in the synthetic dataset being unrepresentative of real data. In this way privacy is increased by the PET but at the cost of losing the trends in data, reducing its utility. Organisations may wish to test the utility of their synthetic data by comparing results found in the synthetic dataset to that of the real dataset to ensure they are comparable.
Conversely in a federated pipeline that does not deploy DP, the utility of the data is maximised by not changing any of its characteristics. This however offers a considerably lower privacy protection against data recovery. Major data recovery risks include raw training data potentially being recoverable without proper protections. This lack of privacy may even prevent anonymised data being used for certain purposes if the risk of anonymised sensitive data being re-identified is deemed too high (see below - legal considerations).
Database considerations
| Baseline | PETs |
| Traditional database storage offering a lower level of privacy. | Greater privacy at rest using differential privacy or fully synthetic data. Partial or hybrid synthetic data may require additional PETs to be stacked to be secure in storage. |
Whilst synthetic data can enhance output privacy, data must still be protected in storage. Threat models exist that may allow for the reconstruction of data including membership inference (to determine if an individual was in the original data), attribute inference (recovery of missing attributes) and reconstruction attacks (recovery of original records). Fully synthetic data may be less at risk of these threats as even if an attack is successful the dataset contains no real data.
Organisations seeking to deploy synthetic data should also consider how their data will be used by researchers, which should inform the level of detail required and the type of release model. If it is deemed that sensitive data could be identified, organisations may wish to stack extra PETs on to their synthetic data such as deploying differential privacy on the synthetic dataset. Whilst this produces extra costs for an organisation, it offers protections for the data in storage.
Compute considerations in output privacy approaches
| Baseline | PETs |
| Compute costs for more traditional approaches to privacy are relatively trivial. | Synthetic data and DP datasets have higher compute costs in generation. These costs scale with the complexity of the original/real datasets. Dynamic synthetic data and global DP have continuous compute overheads. |
Use of synthetic data or DP will incur greater computational overheads during setup than traditional methods such as anonymisation. Synthetic data can be generated through use of general adversarial networks, variational auto encoders or other machine learning mechanisms, which have additional costs compared to traditional anonymisation methods. Moreover, should an organisation seek to create dynamic synthetic data they will face continuous costs every time a new dataset is generated or updated.
DP is more variable in its compute costs, with requirements dependent on the scale and complexity of the dataset alongside the privacy budget. Privacy budgets are set depending on whether the differential privacy is global or local. This toolkit specifically focused on Global Differential Privacy (Global DP) within the context of a PPFL pipeline. Global DP refers to the application of DP techniques at a large scale across an entire database, or dataset collection, rather than on smaller or individual segments. This method involves injecting noise into the entire dataset or to the outputs globally, ensuring that individual data contributions are obscured, thereby protecting individual privacy across the dataset. Global DP incurs additional costs due the noise being injected each time a new query is sent rather than a one off. This is particularly relevant within a federated pipeline where DP is likely to be applied whenever data or a model is called upon.
These computational considerations are critical when planning the deployment of PETs like synthetic data and DP, as they significantly impact both the initial and ongoing resources required for effective data privacy management. By understanding these costs, organisations can better strategize the integration of these technologies into their data processes, ensuring that privacy enhancements do not compromise operational efficiencies.
Legal considerations for output privacy approaches
| Baseline | PETs |
| The use of legacy anonymisation techniques may limit the use cases of the data to restricted environments. Legacy anonymisation techniques may require more frequent review as re-identification techniques and available data change over time, requiring legal input. |
DP data or DP synthetic data can be effectively anonymised, providing the risk of re-identification is reduced to a remote level by adding an appropriate level of noise. Synthetic data can also be effectively anonymised, providing that risks to re-identification, e.g. model inversion attacks, membership inference attacks and attribute disclosure risks are appropriately mitigated. This can be achieved by using DP or other approaches such as removal of outliers. Effectively anonymised data is not subject to data protection law, therefore compliance costs associated with handling personal data are removed. |
In certain cases, the use of DP and synthetic data can effectively anonymise personal data. There are still costs organisations will need to consider, including potentially seeking legal advice to help with determining whether data is truly anonymous, but organisations that seek to make data available may be able to reduce legal and compliance costs, as well as duties associated with sharing and processing data by using DP or synthetic data.
Data protection law does not apply to synthetic data or differential privacy which has been assessed as anonymous, therefore, legal costs associated with ensuring compliance with data protection law are minimised. See the ICO guidance for more information on effectively anonymised data. Additionally, the use of synthetic data or DP can allow organisations to make use of data in circumstances where using identifiable data would have been challenging.
Differential privacy
Both models of differential privacy can make outputs anonymised, if a sufficient level of noise is added.
If non-interactive DP is used, the level of identifiable information is a property of the information itself, which is set for a given privacy budget. Once the data is released, no further queries can adjust the level of identifiability in the data. This can reduce legal costs, as the data does not require continuous oversight of interactions needed for the interactive form of differential privacy.
If an interactive query-based model is used, legal input may be required to put contractual controls in place to mitigate the risk of collusion between various parties querying the data (to pool the results of their queries and increase their collective knowledge of the dataset).
Where DP is configured and managed appropriately, the risk of re-identification of personal data can be reduced to a minimal level, mitigating the risk of incurring potential fines and enforcement action due to failure to anonymise personal data is significantly reduced.
Synthetic data
As above, data protection law does not apply to synthetic data, which has been assessed as anonymous, therefore, legal costs associated with ensuring compliance with data protection law are minimised, e.g. no requirement to fulfil data subject requests. If considered anonymised, testing the identifiability of the synthetic data should be performed over time as new attacks and any new data sources are published which may increase the identifiability of the synthetic data.
Anonymous synthetic data can save time and legal costs associated with obtaining approval for the use of real data as a viable replacement for prototyping and system testing.
Similar considerations may apply when seeking to share synthetic data. Legal input may be required when determining whether synthetic data does not contain personal data or inadvertently reveal personal data, e.g. through inference attacks. The use of differentially private synthetic data generation algorithm can help to reduce the risk of re-identification to a sufficiently low level.
Depending on the release mechanism for the data, organisations may incur legal costs through data sharing agreements and contractual controls that are needed in order to clearly define what users can and cannot do with the data. For example, should data be released to a closed environment which only approved researchers can access, contractual controls should be put in place that state that synthetic data should not be used for making decisions about people, without first assessing and mitigating any bias and inaccuracies in the data. Alternatively, if the data is openly published with no access controls, then no contractual controls or restrictions will apply.
Conclusion
The use of PETs is not a silver bullet to ‘solve’ all privacy concerns your organisation may face, however, adopting these technologies correctly, where appropriate to the organisation’s context and intended use case, has the potential to introduce and/or unlock a range of benefits. Before adopting any PETs, it is important to weigh up the costs of your solution against these benefits to determine whether or not the technology is right for your organisation.
For more information on legal compliance please see the ICO’s PETs guidance.