FCDO: Consular Digital Triage - Written Enquiries LLM
A tool for suggesting relevant guidance and services for British nationals abroad.
Tier 1 Information
Name
Consular Digital Triage - Written Enquiries LLM
Description
FCDO Consular Services receives approximately 100,000 written enquiries from the public every year. The vast majority of these are answered by reusing pre-written and pre-approved templates, with written enquiries being matched to relevant templates.
As part of a wider triage tool to help direct users to relevant services and guidance offered by the FCDO, the FCDO has been developing a new route for users to be able to submit written enquiries. Before users submit a written enquiry, a tool developed by the FCDO will try to highlight the relevant template to a user, providing users with immediate guidance and support for their enquiry. Users will still be able to submit a written enquiry if needed, however the tool is intended to provide users with immediate signposting to relevant guidance or services without the need for the user to submit a written enquiry. This has both benefits for the user, and means FCDO can focus on users who need the most help.
Website URL
N/A
Contact email
Tier 2 - Owner and Responsibility
1.1 - Organisation or department
Foreign, Commonwealth and Development Office
1.2 - Team
Consular Services Department
1.3 - Senior responsible owner
Head of Consular Services
1.4 - External supplier involvement
Yes
1.4.1 - External supplier
Caution Your Blast Ltd
1.4.2 - Companies House Number
7203051
1.4.3 - External supplier role
Caution Your Blast (CYB) was involved in an initial discovery to identify potential options for improving the user experience of contacting the FCDO and looking at routes by which users could be provided with information without needing to contact a member of FCDO staff.
CYB later developed an Alpha, which is now in Beta. This will ultimately be handed over to Kainos (a separate supplier - companies house no. NI019370) to maintain and iterate.
1.4.4 - Procurement procedure type
Call-off contract from an existing commercial framework
1.4.5 - Data access terms
CYB data access is governed by the conditions in the wider call-off contract.
Tier 2 - Description and Rationale
2.1 - Detailed description
The model has 2 main outputs:
- templates - these are long-form guidance templates that advise users on what to do in certain situations - for example, providing advice on what to do if someone has lost their passport outside the UK
- topics - these are short pieces of text that reflect what we think the user might have asked about
A user asking a question will ultimately receive both an answer (templates) and also see information on what questions the AI thinks it was asking (topics).
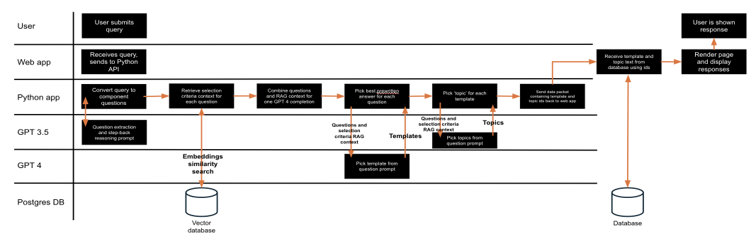
The user writes their question. This question is passed to Azure Cognitive Services, which attempts to remove any personal information a user may have entered (users are discouraged from entering any personal information).
The text submitted by the user is then broken down by a GPT 3.5 model to identify the 3 most significant component question(s).
These questions are compared against potential templates, with the 3 most relevant templates being shortlisted by using an embeddings similarity search. Three templates are chosen for each potential question identified.
These shortlisted answers (up to 9) are then combined with a list of templates unique identifier codes, alongside guidance to the Large Language Model (LLM) on when best to choose each template identifier code (using Retrieval Augmented Generation).
Using the above information the LLM (GPT 4.0) is asked to choose the best template to reply to each question with. A GPT 3.5 model is similarly asked to, using the questions identified, to identify the most relevant topics expressing what it believes the user is asking about, returning the relevant topic unique identifier numbers.
The LLM sends the identifier code for relevant templates and topics to the web app, which then shows to the user the template(s) and topic(s) with the matching identifier number.
The user is therefore not being directly exposed to generated LLM output, minimising the impact of any hallucinations or errors.
If users are unsatisfied with these responses, they are still able to submit a written enquiry which will be reviewed and answered by an FCDO member of staff.
2.2 - Scope
The tool has been designed to choose appropriate templates with which to respond to the most common types of written consular enquiries, choosing from a small library of options. These types of questions vary from questions about how a user should replace their passport when abroad, to what to do if they lose their passport, to what information and supporting documents they need if they want to get married abroad.
The tool is primarily focused on helping users with enquiries not handled elsewhere by the triage - cases where users need urgent assistance in particular is out of scope, as these users are instead encouraged to call or write to the FCDO Consular Contact Centre.
2.3 - Benefit
Providing users with far faster responses and signposting for their written enquiry questions.
2.4 - Previous process
The tool is intended to replace an existing ‘Contact an Embassy’ service, through which users could submit a written enquiry.
2.5 - Alternatives considered
The team also looked at alternatives, such as semantic searches, however users often submit a written enquiry after having failed to find the correct route independently - often because the relevant language can be highly specific.
The LLM approach was chosen because relevant templates could be offered to users even when there were no semantic matches between their enquiry and the relevant answer.
Tier 2 - Decision making Process
3.1 - Process integration
The tool is not intended to impact on the decision-making process. It is intended to provide British nationals with quick and timely signposting to relevant services and guidance before they contact the FCDO. Users can still disregard the information provided, and submit a written enquiry.
3.2 - Provided information
N/A
3.3 - Frequency and scale of usage
The current written enquiries system, which the triage replaces, receives approximately 100,000 messages per year.
3.4 - Human decisions and review
FCDO will review all cases where users proceed to submit a written enquiry, comparing the answer the user was given against what a human would have provided. Spot checks and regular testing will also be conducted on the service more generally to ensure it is continuing to appropriately match user questions to relevant templates.
3.5 - Required training
Public users of the tool do not need any training. Only a limited number of FCDO staff will have the ability to add or remove templates. These members of staff will receive training to help them in this.
3.6 - Appeals and review
Users are able to easily submit a written enquiry to FCDO, which will be reviewed and responded to by a human, if they are unhappy with the response they receive from the tool.
Tier 2 - Tool Specification
4.1.1 - System architecture
{kind=link}
4.1.2 - Phase
Beta/Pilot
4.1.3 - Maintenance
Templates are maintained and can be easily updated using a management tool built for the triage, with access available to a small group of consular staff. Longer-term, this is intended to be merged with the wider Consular case management system to ensure consistency in templates used both by the tool and by staff. Templates are not intended to be constantly iterated, but are instead intended to be quite stable, with improvements being data and user-need led. Maintenance will be managed by FCDO supplier Kainos moving forward.
All scenarios where users choose to submit a written enquiry will be reviewed to ensure that the previous answer received by the user was correct.
Monthly spot-checks will also be conducted to check the tool is still performing against previous baselines.
4.1.4 - Models
Azure Cognitive Services - used to remove personal data from text sent by the user to the AI
Azure OpenAI GPT 3.5 - used to break text from the user into component questions
Azure OpenAI GPT 4 - used to match the component questions to relevant templates, which answer the substantive user question
Azure OpenAI GPT 3.5 - used to select relevant topics, expressing what it thinks the user asked about
Tier 2 - Model Specification
4.2.1 - Model name
GPT
4.2.2 - Model version
GPT-4-32k, version 0613
GPT-3.5-Turbo, version 1106
Different models may be used as the product is iterated, and new models become available.
4.2.3 - Model task
GPT-3.5-Turbo, version 1106 breaks the user question into component questions, and matches the component question to the nearest matching topic headings.
GPT-4-32k, version 0613 matches existing templates to questions, based on RAG guidance.
4.2.4 - Model input
The user query, combined with a guidance explaining how and when the model should choose each template answer.
4.2.5 - Model output
Single or multiple Identifier Numbers, which correspond to templates and topic headings. Template(s) and topic heading(s) are then surfaced on the web app.
4.2.6 - Model architecture
Large Language Model - GPT 4 and 3.5 - https://platform.openai.com/docs/models
GPT 3.5 Turbo - version 1106 https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/models#gpt-35
GPT 4 32k - version 0613 https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/models#gpt-4
4.2.7 - Model performance
Model performance for this specific use case was measured by comparing the performance of the model against FCDO members of staff. This was done by seeing how the model would perform using batches of historic, anonymised enquiries. The template(s) chosen by the model were then compared against the templates chosen by a member of staff. Any differences between templates chosen by the model and templates chosen by a member of staff were reviewed to consider and agree the correct template answer.
Depending on the batch, the tool provided the correct response for 76% to 81% of enquiries.
4.2.8 - Datasets
Anonymised written enquiry data - batches of examples of real questions submitted by users were stripped of any and all personal, identifiable, or specific data. These were then used to refine the Retrieval Augmented Generation (RAG) prompt / matching guidance to the LLM, comparing the ability of the model to choose the correct template against a human.
4.2.9 - Dataset purposes
The batches were used to continually refine the RAG prompt / matching guidance sent to the LLM throughout development, with new batches of data being continually created and used to reduce the risk of overfitting.
Tier 2 - Data Specification
4.3.1 - Source data name
Consular written enquiries selection criteria
4.3.2 - Data modality
Text
4.3.3 - Data description
Guidance on when to choose relevant templates
4.3.4 - Data quantities
Prompts were refined using approximately 600 anonymised text-based test questions.
4.3.5 - Sensitive attributes
N/A - Cleaned of personal data.
4.3.6 - Data completeness and representativeness
Data reflected written enquiries received by Consular Services over multiple months
4.3.7 - Source data URL
N/A
4.3.8 - Data collection
Data was initially collected as written enquiries.
Data was repurposed to help FCDO answer written enquiries by identifying trends, and improving suggestions to users based on what template answers historic written enquiries have received in response.
4.3.9 - Data cleaning
Data was manually reviewed and cleaned by an FCDO member of staff of any and all potential information that could make an individual in any way identifiable before being used.
4.3.10 - Data sharing agreements
No data sharing agreements are in place, outside of those with commercial partners, as no third party data is being shared.
4.3.11 - Data access and storage
Original dataset kept in Microsoft Dynamics-based written enquiries response service. FCDO staff and Kainos administrators have access to this information, as well as limited access for CYB developers. Written enquiries are kept for a period of 30 days as standard with the option of marking some as non-deletable where required.
The digital triage service also collects audit records in a RDS (PostgreSQL) database for enquiry search results (redacted), written enquiry form submissions, page views and user feedback responses which are also exported as a CSV file to an encrypted AWS S3 bucket where they are processed into a data pipeline. The CYB project team use this data to analyse the accuracy and effectiveness of the triage service. This data is stored for a maximum of 6 months. Only a limited number of administrators have access to this AWS environment via multi-factor authentication and IAM role-based permissions.
As part of the live service, enquiries entered by users are first redacted using Azure Cognitive Services to strip out personally identifiable information (PII) prior to including it in any prompts sent to Azure OpenAI. When entering information, users are also asked not to provide personal details.
Tier 2 - Risks, Mitigations and Impact Assessments
5.1 - Impact assessment
A Data Protection Impact Assessment (DPIA) was completed on 15th March 2024. Summary: The risk rating is Medium. The tool will not be used to make impactful decisions about a user, and users retain the ability to escalate their query to a human. Users will be encouraged not to insert personal data, and Azure Cognitive Services will also be used to remove personal data before the query is exposed to the LLM.
The tool will be kept under review, with performance closely monitored to ensure it continues to perform as expected.
5.2 - Risks and mitigations
Risk of hallucination - this has been mitigated by effectively placing an air gap between the LLM and user. The LLM chooses relevant templates and topics, and then passes a Template or Topic Identifier Number to the web app. The web app then presents users with templates and topics with corresponding identifier numbers. Therefore, the worst scenario that can possibly happen is that a user is either presented with irrelevant (but still valid) templates, or alternatively the LLM hallucinates a Template or Topic Identifier Number for a template or topic that doesn’t exist - in which case the user would not be presented with a template or topic.
Risk of user data being mishandled - users are asked not to enter personal information as part of their question. There is a process in place to remove personal information from queries using Azure Cognitive Services before they are exposed to the LLM. The LLM itself however is entirely within the FCDO estate, meaning there is no risk of user data being exposed more widely. Note, however, that Azure do store logs of OpenAI data, for up to 30 days to facilitate human abuse monitoring. This was flagged during the DPIA and the outcome being that the redacting of PII mitigates any potential negative impact of this and overall it was considered beneficial to keep this monitoring in place to alert FCDO of any negative uses.
Security risks - the system has undergone an IT Health Check, including security testing, to ensure it could not be made to act in an unplanned way when released to the public as part of the pilot phase.